久々にトピックモデルの記事です。
トピックモデルを実行した時、各トピックが結局何の話題で構成されているのかを確認するのは結構面倒です。
また、各トピック間の関係などもなかなか掴みづらく解釈しにくいところがあります。
この問題が完全に解決するわけではないのですが、
pyLDAvisと言うライブラリを使うと、各トピックを構築する単語や、トピック間の関係性を手軽に可視化することができます。
しかもインタラクティブな可視化になっており、ポチポチ動かせるので眺めてみるだけで楽しいです。
まずは、可視化するモデルがないことには始まらないので、いつものライブドアニュースコーパスでモデルを学習しておきます。
トピック数はいつもより大目に20としました。(雑ですみません。いつも通り、前処理も適当です。)
import pandas as pd
import MeCab
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# データの読みこみ
df = pd.read_csv("./livedoor_news_corpus.csv")
# ユニコード正規化
df["text"] = df["text"].str.normalize("NFKC")
# アルファベットを小文字に統一
df["text"] = df["text"].str.lower()
# 分かち書きの中で使うオブジェクト生成
tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd")
# ひらがなのみの文字列にマッチする正規表現
kana_re = re.compile("^[ぁ-ゖ]+$")
def mecab_tokenizer(text):
# テキストを分かち書きする関数を準備する
parsed_lines = tagger.parse(text).split("\n")[:-2]
surfaces = [l.split('\t')[0] for l in parsed_lines]
features = [l.split('\t')[1] for l in parsed_lines]
# 原型を取得
bases = [f.split(',')[6] for f in features]
# 品詞を取得
pos = [f.split(',')[0] for f in features]
# 各単語を原型に変換する
token_list = [b if b != '*' else s for s, b in zip(surfaces, bases)]
# 名詞,動詞,形容詞のみに絞り込み
target_pos = ["名詞", "動詞", "形容詞"]
token_list = [t for t, p in zip(token_list, pos) if p in target_pos]
# アルファベットを小文字に統一
token_list = [t.lower() for t in token_list]
# ひらがなのみの単語を除く
token_list = [t for t in token_list if not kana_re.match(t)]
# 数値を含む単語も除く
token_list = [t for t in token_list if not re.match("\d", t)]
return " ".join(token_list)
# 分かち書きしたデータを作成する
df["text_tokens"] = df.text.apply(mecab_tokenizer)
print(df["text_tokens"][:5])
"""
0 読売新聞 連載 直木賞 作家 角田光代 初 長編 サスペンス 八日目の蝉 檀れい 北乃きい ...
1 アンテナ 張る 生活 映画 おかえり、はやぶさ 公開 文部科学省 タイアップ 千代田区立神田...
2 全国ロードショー スティーブン・スピルバーグ 待望 監督 最新作 戦火の馬 アカデミー賞 有...
3 女優 香里奈 都内 行う 映画 ガール 公開 女子高生 限定 試写 会 サプライズ 出席 女...
4 東京都千代田区 内幸町 ホール 映画 キャプテン・アメリカ/ザ・ファースト・アベンジャー 公...
Name: text_tokens, dtype: object
"""
# テキストデータをBOW形式に変換する
tf_vectorizer = CountVectorizer(
token_pattern='(?u)\\b\\w+\\b',
max_df=0.90,
min_df=10,
)
tf = tf_vectorizer.fit_transform(df["text_tokens"])
# LDAのモデル作成と学習
lda = LatentDirichletAllocation(n_components=20)
lda.fit(tf)
さて、この後が本番です。
pyLDAvisのドキュメントはこちらですが、
scikit-learnのLDAの可視化の方法はこっちのnotebookを参照すると良いです。
Jupyter Notebook Viewer pyLDAvis.sklearn
pyLDAvis.sklearn.prepareに、LDAのモデル、BOW(かtf-idf)の学習に用いたデータ、変換に用いた辞書を順番に渡すだけです。
jupyter notebook 上で結果を表示するためにpyLDAvis.enable_notebook()というメソッドも呼び出しています。
import pyLDAvis
import pyLDAvis.sklearn
# jupyter notebookで結果を表示するために必要
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(
lda, # LDAのモデル (LatentDirichletAllocation のインスタンス)
tf, # BOWデータ (sparse matrix)
tf_vectorizer, # CountVectorizer もしくは TfIdfVectorizer のインスタンス
)
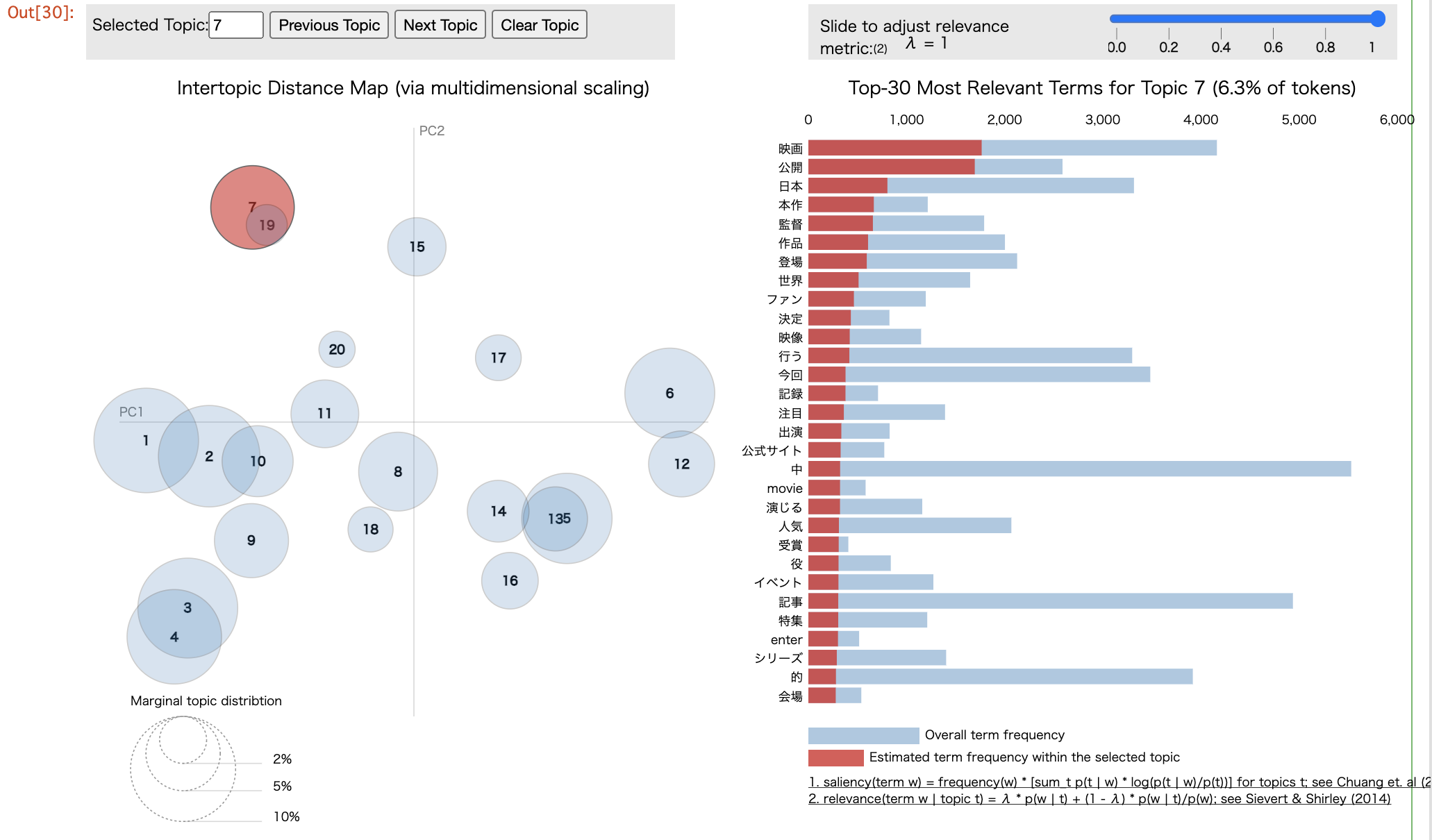
実行すると、以下のような図が表示されます。blogに貼ったのは画像ですが、実際は左の散布図で注目するトピックを切り替えたり、
右側の単語一覧から単語を選択することで、各トピックにその単語がどれだけ含まれるかみることができます。
次のように、 prepare メソッドの戻り値を受け取っておいて、 pyLDAvis.save_htmlメソッドに渡すことで、htmlとして保存することもできます。
このブログにも貼っておくので、是非触ってみてください。
HTMLファイルへのリンク: ldavis-sample
7番目と19番目や、5番目と13番目のトピックが大きくかぶっていて、トピック数が少し多すぎたかなとか、そう言った情報も得られますし、
単語の一覧から各トピックが何の話題なのかざっくりとつかめますね。
表示する単語数は、 R(デフォルト30)と言う引数で指定できます。
また、左側のトピックの位置関係表示に使う次元削減方法は、mdsと言う引数で変更もできます。
指定できるのは現在のところ、pcoa, mmds, tsne の3種類です。