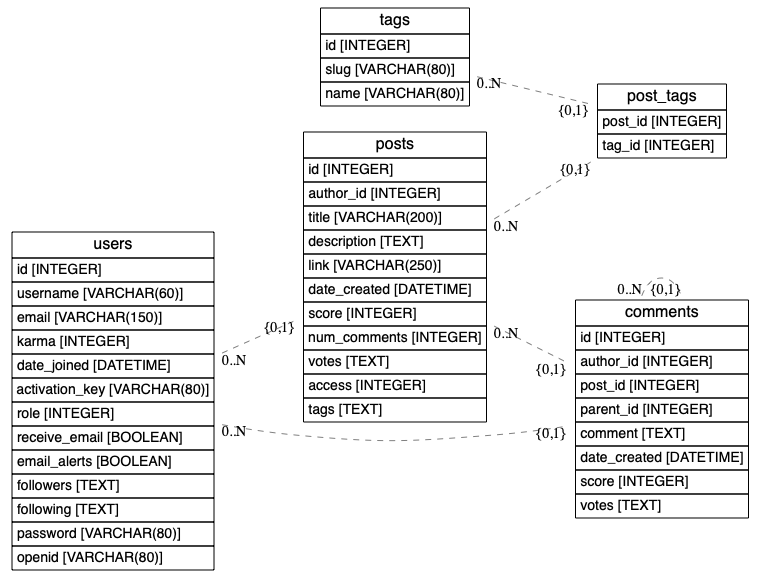
以前からER図をいい感じに出力できるツールを探していたのですが、ERAlchemyというのを知ったので使ってみました。
リポジトリ:Alexis-benoist/eralchemy
PyPI: ERAlchemy
Pythonで実装されたコマンドラインツールということで、Homebrewか、pipでインストールできます。
# どちらか行う。
$ brew install eralchemy
$ pip install eralchemy
自分はbrewのほうでインストールしました。
内部でgraphvizを使っているそうなので、もしかしたら事前にインストールしておく必要があるかもしれません。
既存のデータベースから作図する機能もあるようなのですが、自分はerファイルというテキストファイルから作成する方法で使っています。
erファイルのルールですが、ERAlchemyのページには(今のところ)簡単な例以上の説明は無いようです。
元々erdというツールの影響を受けて作られたそうで、erファイルの書式等はerdのドキュメントを読んで試すのが良さそうです。
ERAlchemy was inspired by erd, though it is able to render the ER diagram directly from the database and not just only from the ER markup language.
リレーションに使える記号の一覧を、ERAlchemyのソースコード中から見つけ出したりしてたのですが、無駄な手間でした。
僕も素直にerdのドキュメントを読めばよかったです。
ちなみにこちらから分かる通り、[*?+1]の4種類と未指定が使えます。
https://github.com/Alexis-benoist/eralchemy/blob/master/eralchemy/models.py
class Relation(Drawable):
""" Represents a Relation in the intermediaty syntax """
RE = re.compile(
'(?P[^\s]+)\s*(?P[*?+1])--(?P[*?+1])\s*(?P[^\s]+)') # noqa: E501
cardinalities = {
'*': '0..N',
'?': '{0,1}',
'+': '1..N',
'1': '1',
'': None
}
さて、使い方は簡単で、次のコマンドで動きます。
eralchemy -i ‘入力ファイル(erファイル)’ -o ‘出力ファイル(pdfやpngなど)’
サンプルファイルを用意していただけてるので、curlでもってくるところからやってみましょう。
$ curl 'https://raw.githubusercontent.com/Alexis-benoist/eralchemy/master/example/newsmeme.er' > markdown_file.er
$ eralchemy -i markdown_file.er -o erd_from_markdown_file.png
これで、画像ファイルが生成されました。(ブログに貼るためにpngファイルにしましたが、通常はpdfの方が使いやすいかと思います。)
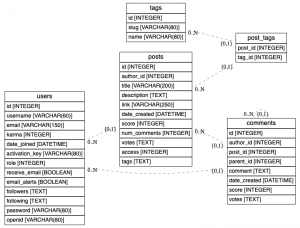
erファイルの中身も少しみておきましょう。
まず、テーブル定義は次のように指定します。
[tags]
*id {label:"INTEGER"}
slug {label:"VARCHAR(80)"}
name {label:"VARCHAR(80)"}
{label:hogehoge}は省略できます。
そしてリレーションは次のように指定します。
users *--? posts
posts *--? comments
users *--? comments
comments *--? comments
tags *--? post_tags
posts *--? post_tags
この例は全て 0以上 対 0or1 のリレーションですが、+で1以上、1で厳密に一つを指定できます。
サンプルの中では使われていませんが、
erdの方のドキュメントを見る限りでは、背景色やフォントの指定などもできそうなので、色々試してみたいと思います。