Pythonでレーダーチャートを書きたくなり、matplotlibでやってみたのでそのメモです。
公式にサンプルがあるのですが、2020年09月 現在うまく動きません。
参考: api example code: radar_chart.py
実装自体も、PolarAxesクラスを継承してメソッドを書き換えるかなり仰々しいものですし、
メモリが円形のままで、僕が望む形ではなかったのでゼロベースでやってみました。
まずライブラリをインポートして、適当にデータを作っておきます。
データはレーダーチャートで可視化する値とそれぞれのラベルがあれば良いです。
import matplotlib.pyplot as plt
import numpy as np
values = np.array([31, 18, 96, 53, 68])
labels = [f"データ{i}" for i in range(1, len(values)+1)]
さて、レーダーチャートですが、見栄えにこだわりがなければ簡単に書くことができます。
matplotlibで極座標のグラフを作り、一周ぐるっとplotするだけです。
簡易版ですがそのコードを先に紹介します。
# 多角形を閉じるためにデータの最後に最初の値を追加する。
radar_values = np.concatenate([values, [values[0]]])
# プロットする角度を生成する。
angles = np.linspace(0, 2 * np.pi, len(labels) + 1, endpoint=True)
fig = plt.figure(facecolor="w")
# 極座標でaxを作成。
ax = fig.add_subplot(1, 1, 1, polar=True)
# レーダーチャートの線を引く
ax.plot(angles, radar_values)
# レーダーチャートの内側を塗りつぶす
ax.fill(angles, radar_values, alpha=0.2)
# 項目ラベルの表示
ax.set_thetagrids(angles[:-1] * 180 / np.pi, labels)
ax.set_title("レーダーチャート", pad=20)
plt.show()
出力がこちらです。
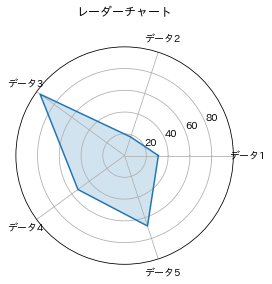
これでも最低限の要件は満たせますね。ただ、データを表してる青の線が真っ直ぐなのに、
その目安となるメモリ線が円形なのが気になります。
また、普通の曲座標と違って、ラベルを上を始点にして時計回りにしたいです。
このラベルの開始位置と回転方向を変えるのは簡単なのですが、メモリを多角形にするのはまともに取り組むと非常に大変です。
(公式サンプルの様なClassを継承しての大がかりな改修が必要になります。)
なので、アプローチを変えてみました。
matplotlibの機能で引いてくれるメモリ線は全部消してしまいます。
そして、定数値のレーダーチャートとして、灰色の線を自分で引きました。
出来上がったコードがこちらです。
# 多角形を閉じるためにデータの最後に最初の値を追加する。
radar_values = np.concatenate([values, [values[0]]])
# プロットする角度を生成する。
angles = np.linspace(0, 2 * np.pi, len(labels) + 1, endpoint=True)
# メモリ軸の生成
rgrids = [0, 20, 40, 60, 80, 100]
fig = plt.figure(facecolor="w")
# 極座標でaxを作成
ax = fig.add_subplot(1, 1, 1, polar=True)
# レーダーチャートの線を引く
ax.plot(angles, radar_values)
# レーダーチャートの内側を塗りつぶす
ax.fill(angles, radar_values, alpha=0.2)
# 項目ラベルの表示
ax.set_thetagrids(angles[:-1] * 180 / np.pi, labels)
# 円形の目盛線を消す
ax.set_rgrids([])
# 一番外側の円を消す
ax.spines['polar'].set_visible(False)
# 始点を上(北)に変更
ax.set_theta_zero_location("N")
# 時計回りに変更(デフォルトの逆回り)
ax.set_theta_direction(-1)
# 多角形の目盛線を引く
for grid_value in rgrids:
grid_values = [grid_value] * (len(labels)+1)
ax.plot(angles, grid_values, color="gray", linewidth=0.5)
# メモリの値を表示する
for t in rgrids:
# xが偏角、yが絶対値でテキストの表示場所が指定される
ax.text(x=0, y=t, s=t)
# rの範囲を指定
ax.set_rlim([min(rgrids), max(rgrids)])
ax.set_title("レーダーチャート", pad=20)
plt.show()
出力がこちら。
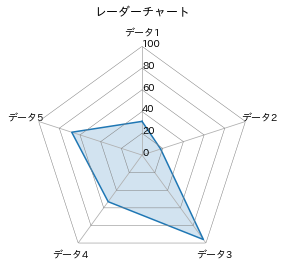
自分がイメージしていたのに近いものが作れました。
コード中にコメントを全部入れたので、ここからさらに見た目を変える場合はすぐ改良できると思います。