scikit-learnで学習した決定木の学習結果を確認するにはライブラリを使うのが便利ですが、
自分でも直接取得してみたかったので方法を調べてみました。
参考:
dtreevizで決定木の可視化
graphvizで決定木を可視化
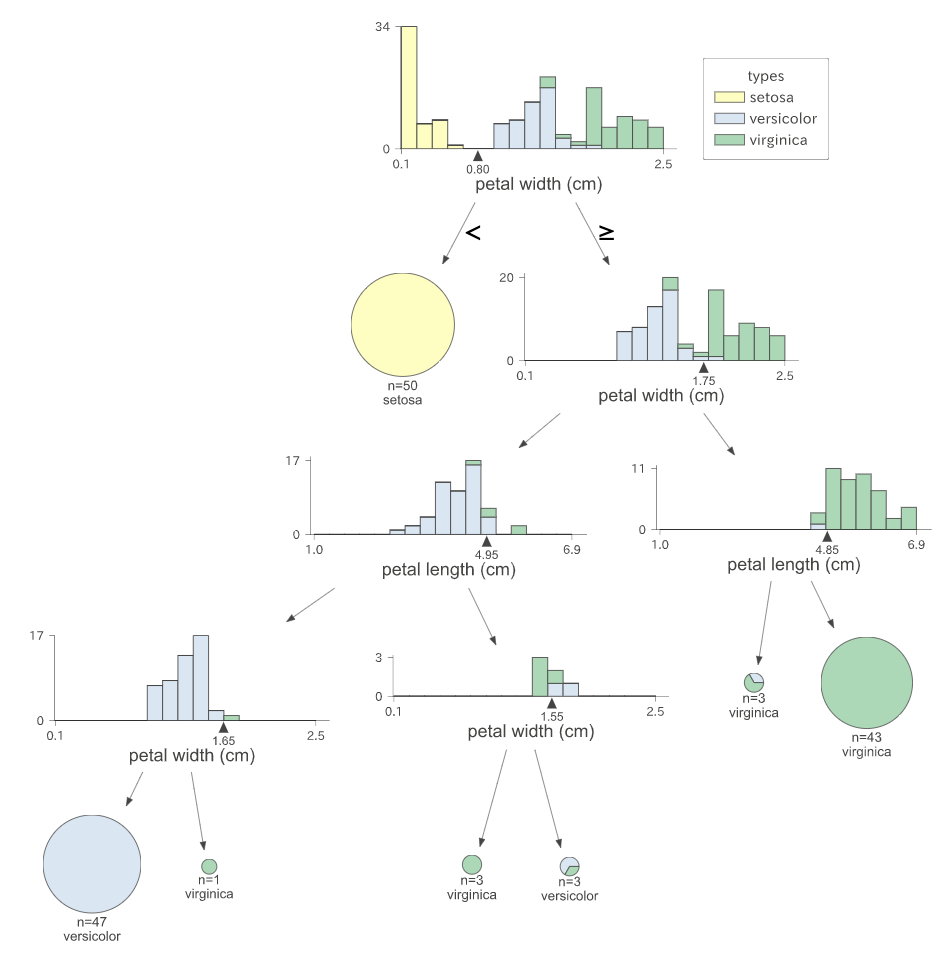
とりあえず、 iris を学習しておきます。dtreevizの記事とパラメーターを揃えたので、
この後の結果はそちらと見比べていただくとわかりやすいです。
ただし、最初の分岐が2パターンあって乱数でどちらになるか決まるので、運が悪いと結果が変わります。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
clf = DecisionTreeClassifier(min_samples_split=5)
clf.fit(
iris.data,
iris.target
)
"""
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=5,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
"""
ロジスティック回帰などであれば、係数が coef_に入っているだけなので簡単なのですが、
決定木の場合読み解くのに少し手間がかかります。
その辺りのことは、ドキュメントにも
Understanding the decision tree structureとしてまとめてあるのでこちらも参照しながら読み解いてみました。
必要な情報は clf.tree_の属性としてまとまっているので順番に取り出してみます。
# ノードの数
n_nodes = clf.tree_.node_count
print(n_nodes)
# 13
# 各ノードに振り分けられた学習データの数。
node_values = clf.tree_.value
# 各ノードの左の子ノード。 葉の場合は -1
children_left = clf.tree_.children_left
print(children_left)
# [ 1 -1 3 4 5 -1 -1 8 -1 -1 11 -1 -1]
# 各ノードの右の子ノード。 葉の場合は -1
children_right = clf.tree_.children_right
print(children_right)
# [ 2 -1 10 7 6 -1 -1 9 -1 -1 12 -1 -1]
# 分割に使う特徴量。 葉の場合は-2
feature = clf.tree_.feature
print(feature)
# [ 3 -2 3 2 3 -2 -2 3 -2 -2 2 -2 -2]
# 分割に使う閾値。 葉の場合は-2
threshold = clf.tree_.threshold
print(threshold)
"""
[ 0.80000001 -2. 1.75 4.95000005 1.65000004 -2.
-2. 1.55000001 -2. -2. 4.85000014 -2.
-2. ]
"""
要するに、各ノードが配列の要素に対応しており、
それぞれ配列に、左の子ノード、右の子ノード、分割に使う特徴量、分割に使う閾値が順番に入っています。
これらの情報を日本語に変化して表示すると次の様になるでしょうか。
for i in range(n_nodes):
print("\nノード番号:", i)
if children_left[i] == -1:
print(" このノードは葉です。")
print(" 予測結果: ")
for v, t in zip(node_values[i][0], iris.target_names):
print(" "+t+": ", round(v/sum(node_values[i][0]), 3))
else:
print(
" "+iris.feature_names[feature[i]],
"が",
round(threshold[i], 3),
"未満の場合、ノード:",
children_left[i],
"に進み、それ以外の場合は、",
children_right[i],
"に進む。"
)
出力結果のテキストはこちらです。
ノード番号: 0
petal width (cm) が 0.8 未満の場合、ノード: 1 に進み、それ以外の場合は、 2 に進む。
ノード番号: 1
このノードは葉です。
予測結果:
setosa: 1.0
versicolor: 0.0
virginica: 0.0
ノード番号: 2
petal width (cm) が 1.75 未満の場合、ノード: 3 に進み、それ以外の場合は、 10 に進む。
ノード番号: 3
petal length (cm) が 4.95 未満の場合、ノード: 4 に進み、それ以外の場合は、 7 に進む。
ノード番号: 4
petal width (cm) が 1.65 未満の場合、ノード: 5 に進み、それ以外の場合は、 6 に進む。
ノード番号: 5
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 1.0
virginica: 0.0
ノード番号: 6
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 0.0
virginica: 1.0
ノード番号: 7
petal width (cm) が 1.55 未満の場合、ノード: 8 に進み、それ以外の場合は、 9 に進む。
ノード番号: 8
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 0.0
virginica: 1.0
ノード番号: 9
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 0.667
virginica: 0.333
ノード番号: 10
petal length (cm) が 4.85 未満の場合、ノード: 11 に進み、それ以外の場合は、 12 に進む。
ノード番号: 11
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 0.333
virginica: 0.667
ノード番号: 12
このノードは葉です。
予測結果:
setosa: 0.0
versicolor: 0.0
virginica: 1.0
先日可視化した結果とバッチリ対応していますね。