久々のNetworkXの記事です。
今回はグラフを可視化するときに、明示的に頂点の座標を指定する方法を紹介します。
ドキュメントの Docs » Reference » Drawing
のページを見ると、draw_networkxなどの可視化関数がposという引数を受け取ることがわかります。
ここに、{頂点:(x座標, y座標), …} という形式の辞書を渡してあげると、可視化するときにその座標にノードを配置できます。
これを使って頂点を格子点においたり、一直線に並べたりできます。
いい感じに座標の辞書を作ってくれる関数もいくつか用意されているのですが、
今回は自分で直接円周上のてんを定義してやってみます。
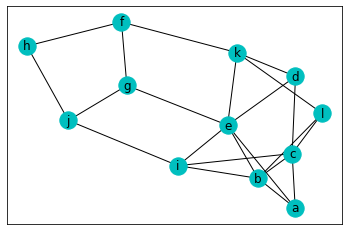
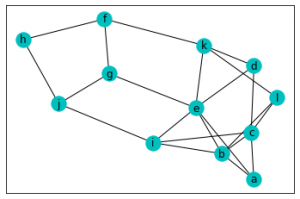
まず一つ目の例は座標は指定せずにそのまま可視化したものです。
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
# 12個の頂点と、ランダムに引いた辺を持つグラフを定義
node_labels = "abcdefghijkl"
G = nx.Graph()
G.add_nodes_from(node_labels)
for i in range(len(G.nodes)):
for j in range(i+1, len(G.nodes)):
if np.random.uniform() < 0.3:
G.add_edge(node_labels[i], node_labels[j])
# 座標を指定せずに描写する
nx.draw_networkx(G, node_color="c")
plt.show()
結果がこちら。頂点はある程度バラバラに配置されていますね。
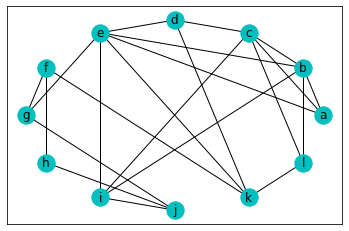
次にグラフはそのままで座標を指定してみます。
# 各頂点に対して円周上の座標を割り当てる
pos = {
n: (np.cos(2*i*np.pi/12), np.sin(2*i*np.pi/12))
for i, n in enumerate(G.nodes)
}
print(pos)
'''
{'a': (1.0, 0.0),
'b': (0.8660254037844387, 0.49999999999999994),
'c': (0.5000000000000001, 0.8660254037844386),
'd': (6.123233995736766e-17, 1.0),
'e': (-0.4999999999999998, 0.8660254037844388),
'f': (-0.8660254037844387, 0.49999999999999994),
'g': (-1.0, 1.2246467991473532e-16),
'h': (-0.8660254037844388, -0.4999999999999998),
'i': (-0.5000000000000004, -0.8660254037844384),
'j': (-1.8369701987210297e-16, -1.0),
'k': (0.5, -0.8660254037844386),
'l': (0.8660254037844384, -0.5000000000000004)}
'''
# 指定した座標を用いてグラフを可視化する
nx.draw_networkx(G, pos=pos, node_color="c")
plt.show()
結果がこちらです。
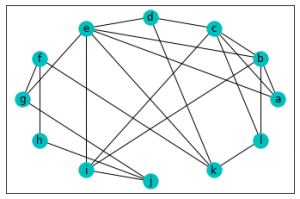
きちんと円周上に頂点が並びました。