前回の記事で、MeCabの最小コスト法について説明しました。
参考: MeCabに実装されている最小コスト法について
その記事は形態素解析のアルゴリズムの話がメインで、説明用に作った図のコードなどは本筋とズレるので掲載しませんでしたが、せっかく書いたプログラムがもったいないのでこの記事で紹介します。
まず、この図を作ります。

最初に、入力テキスト「すもももももももものうち」を区切れる位置全部で区切って、単語候補のデータを作ります。(あくまでも作図用の実装です。MeCab自体は実はもっと効率の良い方法をとっています。また、このプログラムでは開始位置や終了位置を文字数基準で数えていますが、MeCabの内部ではバイト単位で数えてるようです。)
import glob
import pandas as pd
from graphviz import Digraph
# 元のテキスト
text = "すもももももももものうち"
start_list = [] # 単語開始位置
end_list = [] # 単語終了位置
token_list = [] # 単語
# i文字目からj文字目までを切り出す
for i in range(len(text)):
for j in range(i+1, len(text)+1):
start_list.append(i)
end_list.append(j)
token_list.append(text[i: j])
# データフレームにまとめる
df = pd.DataFrame(
{
"start": start_list,
"end": end_list,
"token": token_list,
}
)
print(len(df))
# 78
print(df.sample(5))
"""
start end token
33 3 4 も
66 7 11 もものう
45 4 8 もももも
3 0 4 すももも
54 5 10 ももももの
"""これで、全78個 (78 = 13*12/2) の単語候補と、その位置のデータが揃いました。
続いて、これらの単語の中からIPA辞書に含まれている単語を選びます。
dic_data_dir 変数に、ダウンロードしてきた辞書のパスを指定しておいてください。
参考: MeCabのIPA辞書の中身を確認する
また、この段階で文頭文末記号(BOS/EOS)も追加しておきます。
# コンパイル前の辞書データ (csvファイルたちが保存されているディレクトリを指定)
dic_data_dir = "{辞書データのディレクトリパス}"
ipa_df = pd.DataFrame()
# .csvフィアルを全て読み込みDataFrameに格納する
for csv_path in glob.glob(f"{dic_data_dir}/*.csv"):
tmp_df = pd.read_csv(csv_path, header=None)
ipa_df = ipa_df.append(tmp_df)
print(len(ipa_df))
# 392126
# 辞書に含まれていた単語だけを残す
df = df[df["token"].isin(ipa_df[0])].copy()
print(len(df))
# 25
# BOS, EOSの情報を追加
df = df.append(
pd.DataFrame(
{
"start": [0, len(text)],
"end": [0, len(text)],
"token": ["BOS", "EOS"]
}
)
).copy()
df.reset_index(inplace=True, drop=True)
print(df.tail())
"""
start end token
22 10 11 う
23 10 12 うち
24 11 12 ち
25 0 0 BOS
26 12 12 EOS
"""ここまでで、図中に含まれるノード(単語)の情報は揃いました。次にエッジのデータを作ります。for文を2重に回してもいいのですが、先ほどのDataFrameを二つ用意して、終了位置と開始位置が一致するものを結合するとスマートです。
# 開始位置と終了位置が等しい単語を結合することで、エッジ情報を作成する
df1 = df.rename(columns={"start": "start1", "end": "end1", "token": "token1"})
df2 = df.rename(columns={"start": "start2", "end": "end2", "token": "token2"})
edge_df = pd.merge(left=df1, right=df2, left_on="end1", right_on="start2")
# end2 が 0 のレコードは BOS -> BOSなので消す
edge_df = edge_df[edge_df.end2 > 0].copy()
# start1 が テキスト長に等しいレコードは EOS -> EOSなので消す
edge_df = edge_df[edge_df.start1 < len(text)].copy()
print(edge_df.sample(5))
"""
start1 end1 token1 start2 end2 token2
10 2 3 も 3 4 も
45 10 12 うち 12 12 EOS
19 4 5 も 5 7 もも
25 5 7 もも 7 9 もも
20 4 6 もも 6 7 も
"""これでノードとエッジの情報が揃ったので、graphvizの有向グラフオブジェクトに順番に渡せばOKです。
graph = Digraph(format="png") # グラフオブジェクト生成
graph.attr(rankdir="LR") # 左から右
# ノードを生成する
for i, row in df.iterrows():
# 開始位置が異なる単語を別ノードとして扱うため、nameは{開始位置}-{単語}とする。
# ラベルは{単語}をそのまま使う
graph.node(f"{row['start']}-{row['token']}", row['token'])
# 連続する単語間にエッジを生成する
for i, row in edge_df.iterrows():
graph.edge(
f"{row['start1']}-{row['token1']}",
f"{row['start2']}-{row['token2']}",
)
graph # jupyter notebookに結果を表示する場合はこの行を実行
# graph.render("mecab-lattice") # ファイルに保存する場合はこの行を実行以上で、上のラティスのグラフが生成されます。
前の記事ではもう一個、一部にフォーカスして生起コストと連接コストを掲載した図も作りました。
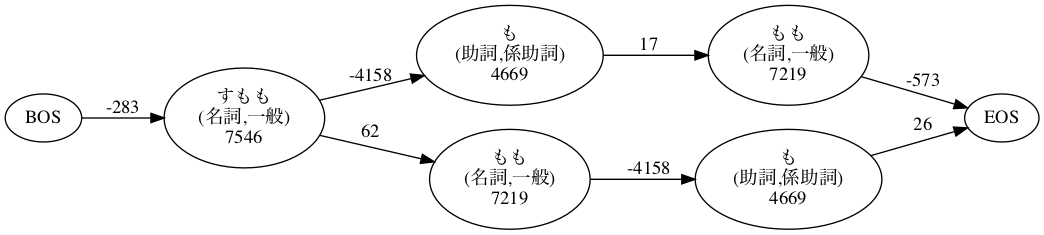
これは構成要素がそんなに多くないので、IPA辞書のデータを逐一参照して生起コストと連接コストの値を拾ってきて、ハードコーディングしました。
graph = Digraph(format="png")
graph.attr(rankdir="LR")
# ノードを生成
graph.node("BOS")
graph.node("EOS")
graph.node("すもも", "すもも\n(名詞,一般)\n7546")
graph.node("も1", "も\n(助詞,係助詞)\n4669")
graph.node("もも1", "もも\n(名詞,一般)\n7219")
graph.node("もも2", "もも\n(名詞,一般)\n7219")
graph.node("も2", "も\n(助詞,係助詞)\n4669")
# エッジを生成
graph.edge("BOS", "すもも", label="-283")
graph.edge("すもも", "も1", label="-4158")
graph.edge("も1", "もも1", label="17")
graph.edge("すもも", "もも2", label="62")
graph.edge("もも2", "も2", label="-4158")
graph.edge("もも1", "EOS", label="-573")
graph.edge("も2", "EOS", label="26")
graph # jupyter notebookに結果を表示する場合はこの行を実行
# graph.render("connection-cost") # ファイルに保存する場合はこの行を実行