半年ほど前から、PyMCを使うようになりました。だいぶ慣れてきたのでこれから数回の記事でPyMCの入門的な内容をまとめていこうと思います。(記事執筆時間の制約等の要因で途中で違うテーマの記事を挟むかもしれませんができるだけ連続させたいです。)
PyMCとは
PyMCはPythonで書かれたオープンソースの確率的プログラミングライブラリです。ベイズ統計モデルを構築、分析し、複雑な統計的問題を解くことができます。PyMCのversion4の開発ではいろいろゴタゴタがありバージョン番号がスキップされたようですが、現在ではverison5がリリースされています。
公式ドキュメントはこちらです。
参考: Home — PyMC project website
特徴としては、線形モデルから複雑な階層モデルまで、幅広いモデルを柔軟に構築できることや、最新のMCMCアルゴリズムを利用して、効率的にサンプリングが行えることが挙げられます。
ただし、柔軟にモデルを構築できる反面で、自分でモデルの内容を実装しないといけないのでscikit-learnのような、既存のモデルをimportしてfit-predictさせたら完結するような単純なAPIにはなっていません。それでも、かなり直感的なAPIにはなっていると感じています。
サンプルコード
一番最初の記事なので、今回は本当に一番単純なサンプルコードを紹介します。これは正規分布に従う標本を生成して、そのパラメーターを推定するというものです。
ダミーデータは平均3, 標準偏差2の正規分布から取りました。
ベイズ推定するので、パラメーターに事前分布が必要です。これは平均の方は平均0、標準偏差10の正規分布、標準偏差の方はsigma=10の半正規分布を設定しました。
ダミーデータ生成からモデルの作成までが以下のコードです。
import pymc as pm
import numpy as np
# ダミーデータを生成
true_mu = 3
true_sigma = 2
np.random.seed(seed=10)
data = np.random.normal(true_mu, true_sigma, size=100)
with pm.Model() as model:
# 事前分布を設定
mu = pm.Normal('mu', mu=0, sigma=10)
sigma = pm.HalfNormal('sigma', sigma=1)
# 尤度関数を設定
likelihood = pm.Normal('likelihood', mu=mu, sigma=sigma, observed=data)ダミーデータの生成分は単純なのでいいですね。
その後が本番です。
PyMCでは、withを使ってコンテキストを生成し、その中に実際のコードを書いていきます。
pm.Normal や pm.HalfNormal など、さまざまな確率分布が用意されていますが、それを使って変数の事前分布を定義しています。
そして、そこで事前分布を設定された変数、mu, sigmaを使って最後の正規分布を定義し、観測値(observed)として用意したダミーデータを渡しています。
Graphvizを導入している環境の場合、次のようにしてモデルを可視化できます。
これはコンテキストの外で行えるので注意してください。(displayしていますが、これはjupyter上に表示することを想定しています。)
g = pm.model_to_graphviz(model)
display(g)出力結果がこちらです。
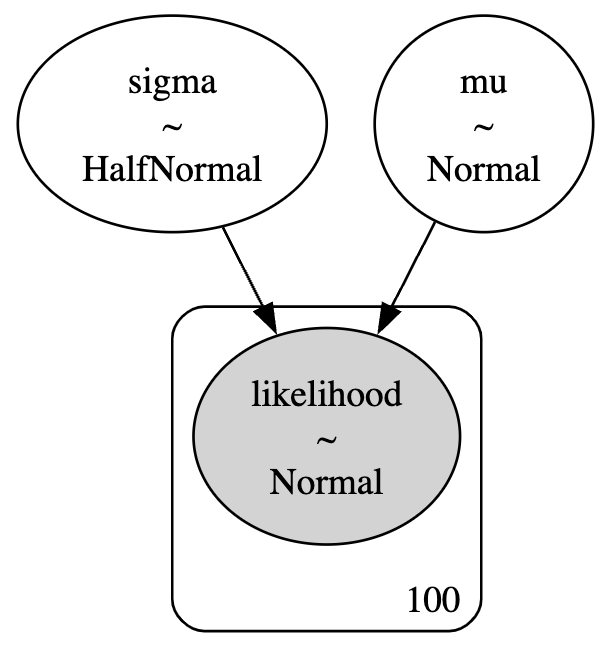
モデルが出来上がったらサンプリングを行います。
サンプリングはコンテキスト内で、pm.sample()メソッドを呼び出すことで行います。
引数としては初期の捨てるサンプル数(tune)と、分析に利用するサンプル数(draws)、さらにサンプル値系列を幾つ生成するかを示すchainsを渡します。
with model:
trace = pm.sample(
draws=1000,
tune=1000,
chains=4,
)
# 以下出力。時間がかかる処理の場合プログレスバーも見れるので助かります。
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
100.00% [8000/8000 00:00<00:00 Sampling 4 chains, 0 divergences]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.サンプルが終わったら要約を表示します。
# サンプルの要約を表示
summary = pm.summary(trace)
print(summary)
# 結果
mean sd hdi_3% hdi_97% mcse_mean mcse_sd ess_bulk ess_tail r_hat
mu 3.155 0.191 2.792 3.506 0.003 0.002 3867.0 2867.0 1.0
sigma 1.933 0.135 1.687 2.191 0.002 0.002 3927.0 3150.0 1.0meanの値を見ると、それぞれ真の値に結構近い値が得られていますね。
以上が、本当に一番シンプルなPyMCの使い方の記事でした。
今後の記事ではもう少し細かい仕様の話や発展的な使い方、ArviZという専用の可視化ライブラリの話などを紹介していきたいと思います。