普段、文章の形態素解析にはMeCabを使用しているのですが、
とあるサンプルコードを動かそうとした時に、その中でNLTKが使われており、思ったように動かなかったのでそのメモです。
ちなみに、 Anaconda で環境を作ったので、 nltk自体はインストールされていました。
~$ python --version
Python 3.6.8 :: Anaconda, Inc.
~$ pip freeze | grep nltk
nltk==3.3
サンプルコードを動かした時にデータエラーがこちら
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
ドキュメントを読むと、何かダウンロードをやらないといけないようです。
こういう、基本的な処理であってもエラーになります。
>>> import nltk
>>> nltk.word_tokenize('hello nltk!')
Traceback (most recent call last):
(略)
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
Searched in:
(略)
**********************************************************************
エラーメッセージを見る限りでは、 ‘punkt’ってのだけで良さそうですが、一気に入れてしまっておきましょう。
~$ python
>>> import nltk
>>> nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
CLI内で完結すると思ったら windowが立ち上がったので少しびっくりしました。
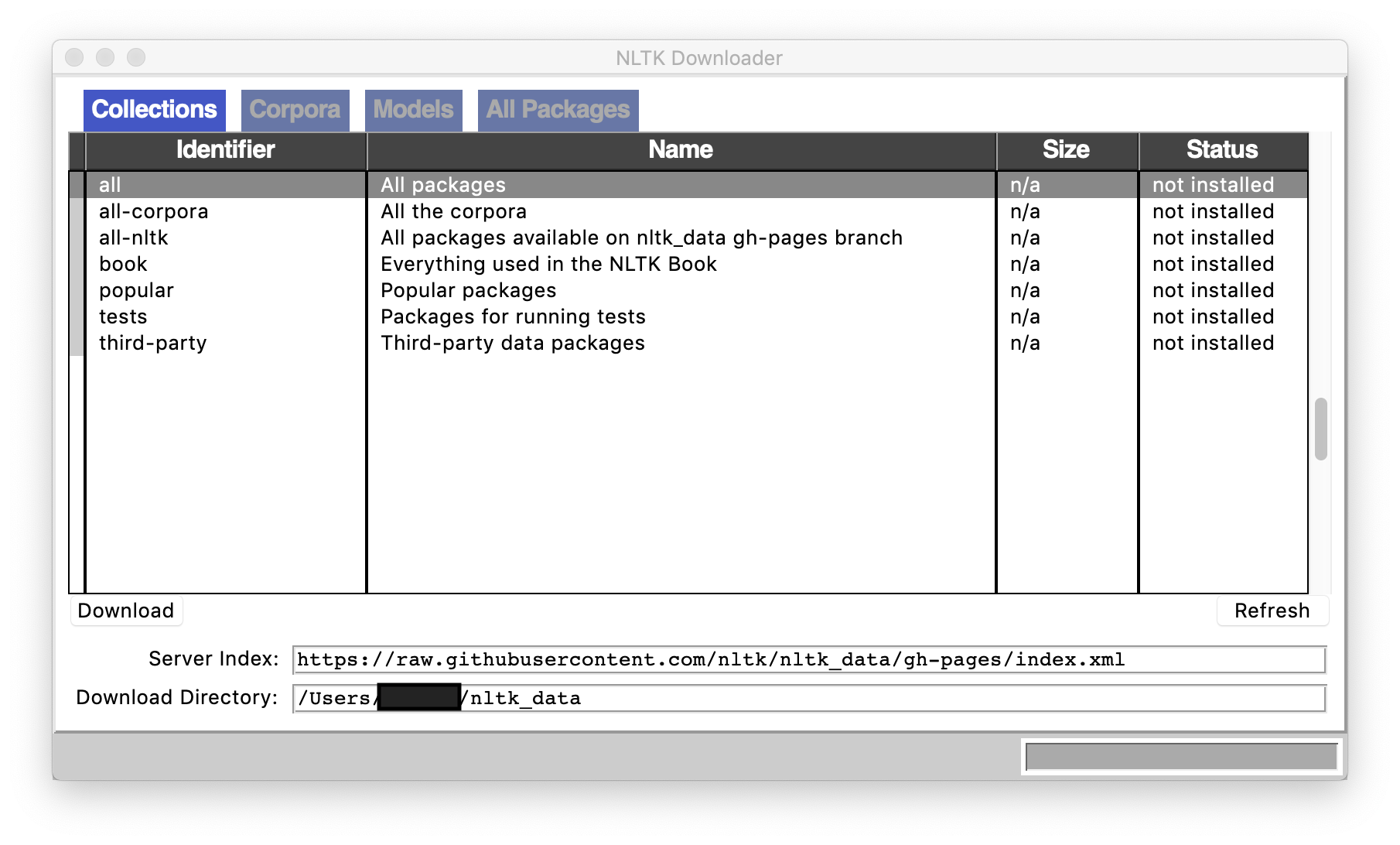
all を選んで Downloadします。
結構時間がかかります。
これで動くようになりました。
>>> import nltk
>>> nltk.word_tokenize("hello nltk!")
['hello', 'nltk', '!']