前回の記事で、MeCabのN-Best解について紹介し、そのコスト計算にバグがあることについて触れました。
参考: MeCabのN-Best解を出力する
2番目以降の解の(生起と連接)コストの総和が1番目の解と同じになってしまうのでしたね。
このバグについて、具体的にどこでどう計算がずれてしまっているのか確認したのでそれを記事にまとめておきます。これを調べる前までは、生起コストと連接コストは正しく取得できて、合計結果だけ上書きされてるんじゃないかなぁと予想していたのですが、実際は連接コストの値が書き換えられていました。ここが正しくて合計が合わないだけなら自分で足し合わせるだけでよかったのでちょっと残念な結果でした。
それでは検証した内容を順番に書いていきます。
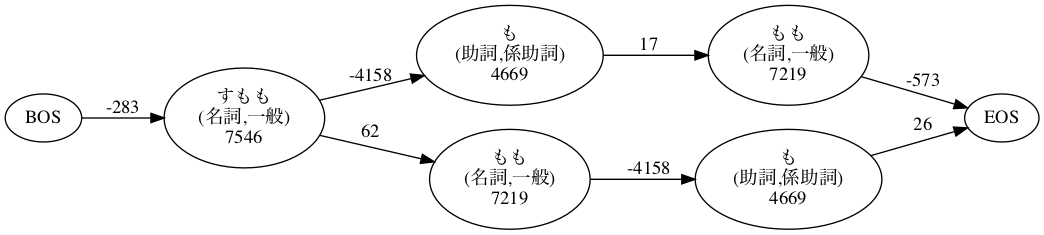
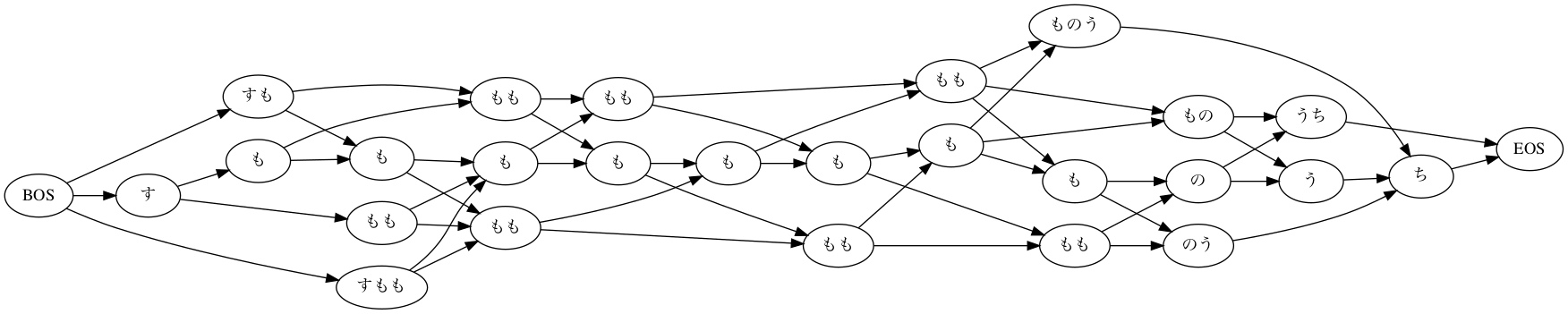
まず、いつもの”すもももももももものうち”で、N-Best解を出力し検証用のサンプルを取得します。特に深い理由はないのですが、 1番目の解(=正しくコストが計算される)と、4番目の解(=コスト計算が誤っている)を見ていきます。
まずは単純に形態素解析していきます。また、コスト計算の結果を検証するために、コストに関する各種情報を出力する設定にして、4番目までのN-Best解を出力します。
import MeCab
import pandas as pd
text = "すもももももももものうち"
# 表層系(%m), 形態素種類(%s), 左文脈id(%phl), 右文脈id(%phr), 単語生起コスト(%c),
# 連接コスト(%pC), 生起コスト+連接コスト(%pn), 生起コスト+連接コストの累積(%pc), 素性(%H)
# を順番に出力する設定でTaggerを生成
tagger = MeCab.Tagger(
" -F %m\\t%s\\t%phl\\t%phr\\t%c\\t%pC\\t%pn\\t%pc\\t%H\\n" +
" -E EOS\\t%s\\t%phl\\t%phr\\t%c\\t%pC\\t%pn\\t%pc\\tEOS\\n"
)
parse_result = tagger.parseNBest(4, text)
print(parse_result)
"""
すもも 0 1285 1285 7546 -283 7263 7263 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 0 262 262 4669 -4158 511 7774 助詞,係助詞,*,*,*,*,も,モ,モ
もも 0 1285 1285 7219 17 7236 15010 名詞,一般,*,*,*,*,もも,モモ,モモ
も 0 262 262 4669 -4158 511 15521 助詞,係助詞,*,*,*,*,も,モ,モ
もも 0 1285 1285 7219 17 7236 22757 名詞,一般,*,*,*,*,もも,モモ,モモ
の 0 368 368 4816 -4442 374 23131 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 0 1313 1313 5796 -5198 598 23729 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS 3 0 0 0 -2484 -2484 21245 EOS
すもも 0 1285 1285 7546 -283 7263 7263 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 0 262 262 4669 -4158 511 7774 助詞,係助詞,*,*,*,*,も,モ,モ
もも 0 1285 1285 7219 17 7236 15010 名詞,一般,*,*,*,*,もも,モモ,モモ
もも 0 1285 1285 7219 62 7281 22291 名詞,一般,*,*,*,*,もも,モモ,モモ
も 0 262 262 4669 -4158 511 22802 助詞,係助詞,*,*,*,*,も,モ,モ
の 0 368 368 4816 -4487 329 23131 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 0 1313 1313 5796 -5198 598 23729 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS 3 0 0 0 -2484 -2484 21245 EOS
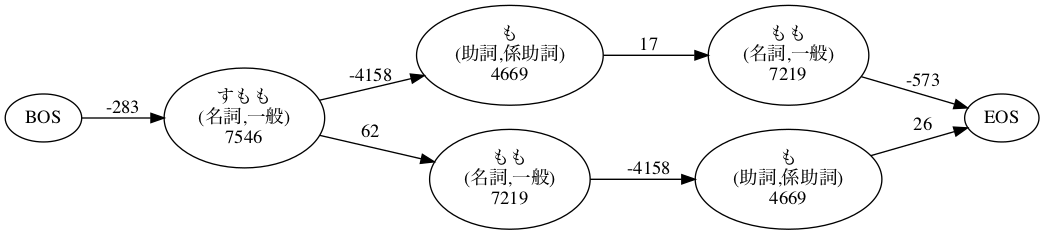
すもも 0 1285 1285 7546 -283 7263 7263 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
もも 0 1285 1285 7219 62 7281 14544 名詞,一般,*,*,*,*,もも,モモ,モモ
も 0 262 262 4669 -4158 511 15055 助詞,係助詞,*,*,*,*,も,モ,モ
もも 0 1285 1285 7219 17 7236 22291 名詞,一般,*,*,*,*,もも,モモ,モモ
も 0 262 262 4669 -4158 511 22802 助詞,係助詞,*,*,*,*,も,モ,モ
の 0 368 368 4816 -4487 329 23131 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 0 1313 1313 5796 -5198 598 23729 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS 3 0 0 0 -2484 -2484 21245 EOS
すもも 0 1285 1285 7546 -283 7263 7263 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
もも 0 1285 1285 7219 62 7281 14544 名詞,一般,*,*,*,*,もも,モモ,モモ
も 0 262 262 4669 -4158 511 15055 助詞,係助詞,*,*,*,*,も,モ,モ
も 0 262 262 4669 -4203 466 15521 助詞,係助詞,*,*,*,*,も,モ,モ
もも 0 1285 1285 7219 17 7236 22757 名詞,一般,*,*,*,*,もも,モモ,モモ
の 0 368 368 4816 -4442 374 23131 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 0 1313 1313 5796 -5198 598 23729 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS 3 0 0 0 -2484 -2484 21245 EOS
"""
コストの総和が4パターンとも全部 21245 になってしまっていますね。
この計算がどこで間違っているのか見ていきましょう。
このままだと非常に扱いにくいので、PandasのDataFrameにします。
# 改行、Tabで順に区切ってDataFrameにする
df = pd.DataFrame(
data=[r.split() for r in parse_result.splitlines()],
columns=[
"表層系", "形態素種類", "左文脈id", "右文脈id", "単語生起コスト",
"連接コスト", "生起コスト+連接コスト", "生起コスト+連接コストの累積", "素性",
]
)
# 数値で取得できた値はint型にしておく
for c in ["形態素種類", "左文脈id", "右文脈id", "単語生起コスト",
"連接コスト", "生起コスト+連接コスト", "生起コスト+連接コストの累積", ]:
df[c] = df[c].astype(int)
# 1番目の解と4番目の解をそれぞれ個別のデータフレームに取り出す
nb1_df = df.iloc[0: 8].copy()
nb4_df = df.iloc[24: 32].copy()
nb4_df.reset_index(inplace=True, drop=True)
これで、nb4_df に今回注目する4番目のN-Best解の情報が入りました。nb1_dfは検証用です。
最初に予想していたのは、”生起コスト+連接コストの累積”だけ書き換えられていて、”生起コスト+連接コスト”の総和は本当は正しい値になっているのではないか?ということです。ただ、この予想は早速外れました。
以下の通り、生起コスト+連接コスト列を足すと21245になってしまいます。
そのためこの累積計算には誤りはなく、正しく足し算されているようです。
print(nb4_df["生起コスト+連接コスト"].sum())
# 21245
次に疑ったのが、”生起コスト+連接コスト” が “生起コスト”と”連接コスト”の和になってないのではないか?ということです。しかしこの点についても問題ありませんでした。
次のコードの通り値を計算してみても、何も矛盾なく全部0になります。
print(nb4_df["生起コスト+連接コスト"]-nb4_df["単語生起コスト"]-nb4_df["連接コスト"])
"""
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
dtype: int64
"""
となると、単語生起コストがそもそも違う?という懸念が出てくるのですが、これも1つ目の解と4つ目の解を見比べてみると一致しており問題ないことがわかります。
print(nb1_df[["表層系", "単語生起コスト", "素性"]])
"""
表層系 単語生起コスト 素性
0 すもも 7546 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
1 も 4669 助詞,係助詞,*,*,*,*,も,モ,モ
2 もも 7219 名詞,一般,*,*,*,*,もも,モモ,モモ
3 も 4669 助詞,係助詞,*,*,*,*,も,モ,モ
4 もも 7219 名詞,一般,*,*,*,*,もも,モモ,モモ
5 の 4816 助詞,連体化,*,*,*,*,の,ノ,ノ
6 うち 5796 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
7 EOS 0 EOS
"""
print(nb4_df[["表層系", "単語生起コスト", "素性"]])
"""
表層系 単語生起コスト 素性
0 すもも 7546 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
1 もも 7219 名詞,一般,*,*,*,*,もも,モモ,モモ
2 も 4669 助詞,係助詞,*,*,*,*,も,モ,モ
3 も 4669 助詞,係助詞,*,*,*,*,も,モ,モ
4 もも 7219 名詞,一般,*,*,*,*,もも,モモ,モモ
5 の 4816 助詞,連体化,*,*,*,*,の,ノ,ノ
6 うち 5796 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
7 EOS 0 EOS
"""
順番は違いますが、名詞一般のすももは7546で、助詞系助詞のもは4669みたいにみていくと何も問題ないことがわかりますね。
ということで最後に残ったのが連接コストです。正直、これの正否を調べるのは面倒だったので後回しにしていたのですがここしか疑うところがなくなってしまいました。
IPA辞書データに含まれている matrix.def から正しいデータを拾ってきて比較検証するしかありません。
比較を効率にするために、次のようなコードを書いてみました。
dic_data_dir = "{コンパイル前の辞書データが含まれているパスを指定}"
# スペース区切りで読み込み
matrix_df = pd.read_csv(f"{dic_data_dir}/matrix.def", delimiter=" ")
# 1列目がindex扱いされてしまっているので再設定
matrix_df.reset_index(inplace=True,)
# 列名修正
matrix_df.columns = ["前の単語の右文脈id", "左文脈id", "辞書から取得した連接コスト"]
# 前の単語の右文脈idの列を作成
nb4_df["前の単語の右文脈id"] = nb4_df["右文脈id"].shift(1)
# 1つ目の単語の前はBOSで、その文脈idは0なのでそれで埋める
nb4_df.loc[0, "前の単語の右文脈id"] = 0
# 結合する
print(pd.merge(
nb4_df,
matrix_df,
left_on=["前の単語の右文脈id", "左文脈id"],
right_on=["前の単語の右文脈id", "左文脈id"],
)[["表層系", "左文脈id", "右文脈id", "連接コスト", "辞書から取得した連接コスト"]])
"""
表層系 左文脈id 右文脈id 連接コスト 辞書から取得した連接コスト
0 すもも 1285 1285 -283 -283
1 もも 1285 1285 62 62
2 も 262 262 -4158 -4158
3 も 262 262 -4203 478
4 もも 1285 1285 17 17
5 の 368 368 -4442 -4442
6 うち 1313 1313 -5198 -5198
7 EOS 0 0 -2484 -2484
"""
これでN-Best解で出力された連接コストと、辞書から取得した連接コストが出力されした。
上から順番にみていくと、4行目(index3の行)で、出力された連接コストが-4203なのに、辞書から取得した連接コストが478になっているところがあります。
これのせいで結果(総和)が本来のコストよりずっと小さくなり、1番目の解と同じになってしまっていたのですね。
さて、今回のサンプルでは連接コストが1カ所誤った値になり総和がズレるということがわかりました。実はより長文で実験したりすると、このように値がズレるところが2カ所以上出てくることもわかっています。ズレる部分が何カ所発生するのか、また何単語目がズレるのかといったことに関する法則性はまだわかっていません。
もしかしたら生起コストの方がずれることもあるのかな?とは思ったのですが今のところそういう例は見つかっていないので一旦は大丈夫そうです。
とはいえ、合計する元データになる連接コストの値自体がずれてしまっているとなると自分で足し合わせて正しい値を得るということは少し面倒ですね。
上のコードみたいに、自分で辞書から連接コストを持ってきてそれを使って足し合わせる必要があります。