matplotlibでオリジナルの配色を使いたかったのでその方法を調べました。基本的にグラフを書くときにそれぞれのメソッドの引数で逐一RGBの値を指定していっても独自カラーを使うことはできるのですが、カラーマップとして作成すると、既存の配色と同じような雰囲気で使うことができるので便利です。
既存のカラーマップでも利用されている、以下の二つのクラスを使って作成できます。
– matplotlib.colors.ListedColormap (N色の色を用意して選択して使う)
– matplotlib.colors.LinearSegmentedColormap (線形に連続的に変化する色を使う)
上記のリンクがそれぞれのクラスのドキュメントですが、別途カラーマップ作成のページもあります。
– Creating Colormaps in Matplotlib — Matplotlib 3.7.1 documentation
まず、ListedColormapのほうから試してみましょう。これはもう非常に単純で、色のリストを渡してインスタンスを作れば完成です。また、name引数で名前をつけておけます。省略するとname=’from_list’となり、わかりにくいので何かつけましょう。名前をつけておくとregisterってメソッドでカラーマップの一覧に登録することができ、ライブラリの既存のカラーマップと同じように名前で呼び出せるようになります。
それでは適当に、赤、緑、青、黄色、金、銀の6色で作ってみます。色の指定はRGBコードの文字列、0~1の実数値3個のタプル、matplotlibで定義されている色であれば色の名前で定義できます。例として色々試すためにそれぞれやってみます。
from matplotlib.colors import ListedColormap
import matplotlib as mpl
import numpy as np
colors = [
"#FF0000", # 赤
(0, 1, 0), # 緑
(0, 0, 1, 1), # 青(不透明度付き)
"yellow",
"gold",
"silver",
]
pokemon_cmap = ListedColormap(colors, name="pokemon")
# 配色リストに登録するとnameで使えるようになる。(任意)
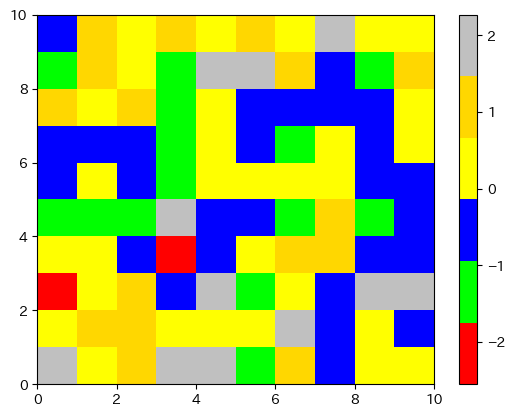
mpl.colormaps.register(pokemon_cmap)これで新しいカラーマップができました。試しに使ってみましょう。文字列でつけた名前を渡してもいいし、先ほど作ったカラーマップのインスタンスを渡しても良いです。
# データを作成
np.random.seed(0)
data = np.random.randn(10, 10)
# 作図
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(1, 1, 1)
psm = ax.pcolormesh(data, cmap="pokemon")
# psm = ax.pcolormesh(data, cmap=pokemon_cmap) # 名前でななくカラーマップインスタンスを渡す場合
fig.colorbar(psm, ax=ax)
plt.show()このような図ができます。色が適当なので見やすくはありませんが、確かに先ほど指定した色たちが使われていますね。
次は連続的に値が変化するLinearSegmentedColormapです。これは色の指定がものすごくややこしいですね。segmentdataっていう、”red”, “green”, “blue”というRGBの3色のキーを持つ辞書データで、それぞのチャネルの値をどのように変化させていくのかを指定することになります。サンプルで作られているデータがこれ。
cdict = {'red': [(0.0, 0.0, 0.0),
(0.5, 1.0, 1.0),
(1.0, 1.0, 1.0)],
'green': [(0.0, 0.0, 0.0),
(0.25, 0.0, 0.0),
(0.75, 1.0, 1.0),
(1.0, 1.0, 1.0)],
'blue': [(0.0, 0.0, 0.0),
(0.5, 0.0, 0.0),
(1.0, 1.0, 1.0)]}各キーの値ですが3値のタプルのリストになっています。
リスト内のi番目のタプルの値を(x[i], y0[i], y1[i]) とすると、x[i]は0から1までの単調に増加する数列になっている必要があります。上の例で言えば、x[0]=0でx[1]=0.5でx[2]=1なので、0~0.5と0.5~1の範囲のredチャンネルの値の変化がy0,y1で定義されています。
値がx[i]からx[i+1]に変化するに当たって、そのチャンネルの値がy1[i]からy0[i+1]へと変化します。上記の”red”の例で言えば値が0〜0.5に推移するに合わせて0から1(255段階で言えば
255)へと変化し、値が0.5~1と推移する間はずっと1です。
y0[i]とy1[i]に異なる値をセットするとx[i]のところで不連続な変化も起こせるみたいですね。
あと、連続値とは言え実装上はN段階の色になる(そのNが大きく、デフォルトで256段階なので滑らかに変化してるように見える)ので、そのNも指定できます。
とりあえず上のcdictデータでやってみましょう。
newcmp = LinearSegmentedColormap('testCmap', segmentdata=cdict, N=256)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
pms = ax.pcolormesh(data, cmap=newcmp)
fig.colorbar(pms, ax=ax)
plt.show()結果がこちら。
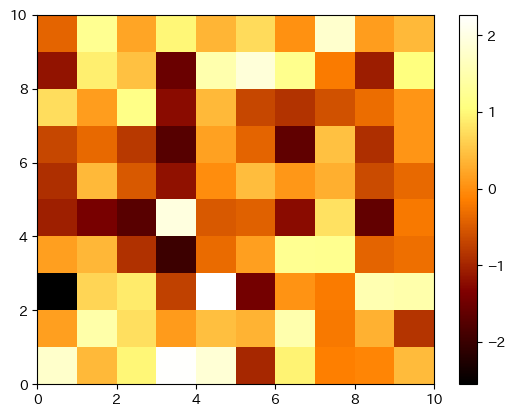
値が小さい時はRGBが全部0なので黒くて、徐々に赤みを増し、途中から緑の値も増え始めるので黄色に向かって、さらに途中から青も増え始めるので最大値付近では白になっていってます。わかりやすいとは言い難いですがなんとなく挙動が理解できてきました。
流石にこのやり方で細かい挙動を作っていくのは大変なので、LinearSegmentedColormap.from_listっていうstaticメソッドがあり、こちらを使うとただ色のリスト渡すだけで等間隔にカラーマップ作ってくれるようです。
また、その時zipを使って区間の調整もできます。使用例の図は省略しますが次のように書きます。(ドキュメントからそのまま引用。)
colors = ["darkorange", "gold", "lawngreen", "lightseagreen"]
cmap1 = LinearSegmentedColormap.from_list("mycmap", colors)
nodes = [0.0, 0.4, 0.8, 1.0]
cmap2 = LinearSegmentedColormap.from_list("mycmap", list(zip(nodes, colors)))これのほうがずっと楽ですね。