前回の記事に続いて、hyperoptの記事です。
前回のサンプルコードでは、100回の探索を経て見つけた最良の値を取得しましたが、
そのほかの結果もみたいということはあると思います。
機械学習のモデルであれば、どのパラメーターが精度に寄与していたとか、
どれはあまり重要でないとか確認したいですからね。
そのような時、hyperopt では Trials というオブジェクトを使います。
ドキュメントのこちらを参考にやってみましょう。
1.3 The Trials Object
from hyperopt import fmin, tpe, hp, Trials
trials = Trials()
best = fmin(
fn=lambda x: x ** 2,
space=hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=100,
trials=trials,
)
print(best)
# 出力
100%|██████████| 100/100 [00:00<00:00, 554.94it/s, best loss: 8.318492974446729e-09]
{'x': 9.120577270352315e-05}
Trials() ってのが途中で出てきた以外は前回の記事と同じコードですね。
この時、trials変数に100回分の履歴が残っています。
試しに一つ見てみましょう。
# trials.trialsに配列型で格納されている結果の一つ目
trials.trials[0]
# 内容
{'state': 2,
'tid': 0,
'spec': None,
'result': {'loss': 96.69903496469523, 'status': 'ok'},
'misc': {'tid': 0,
'cmd': ('domain_attachment', 'FMinIter_Domain'),
'workdir': None,
'idxs': {'x': [0]},
'vals': {'x': [-9.833566746847007]}},
'exp_key': None,
'owner': None,
'version': 0,
'book_time': datetime.datetime(2019, 3, 10, 15, 4, 45, 779000),
'refresh_time': datetime.datetime(2019, 3, 10, 15, 4, 45, 779000)}
$x=-9.833566746847007$ を試したら 損失関数$x^2$の値は$96.69903496469523$ だったということがわかります。
このほか、次のような変数にそれぞれの値の辞書も格納されています。
trials.results
trials.vals
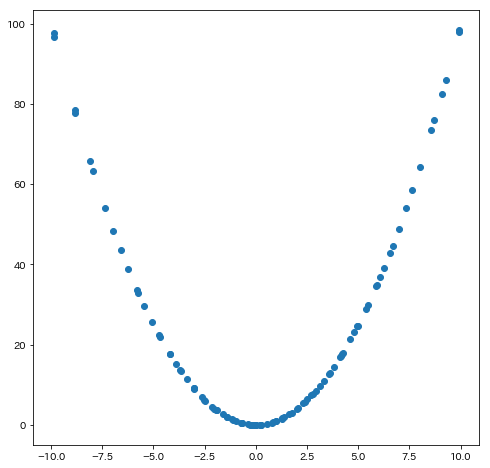
せっかくなので、本当に正解の$x=0$付近を探索していたのか可視化してみましょう。
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(trials.vals["x"], trials.losses())
plt.show()
結果がこちら。
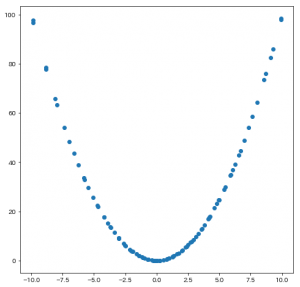
きちんと正解付近に点が密集していますね。