pandasのデータフレームの値をjupyter notebookで確認するとき、
エクセルの条件付き書式のようにセルの値によって色を塗ったりするとわかりやすくなることが多くあります。
ネットで少し探せば、すぐにコードが出てくるのでよく理解せずに background_gradient などを使っていましたが、
先日のPyConで、@komo_frさんのセッション、pandasのStyling機能で強化するJupyter実験レポートを聞いて、ちゃんと体系立てて覚えて使おうというモチベーションが湧いてきたので、ドキュメントを読み始めました。
先述の background_gradient とか、 highlight_null とか 便利関数が用意されているのですが、
その前に基本から紹介していこうと思います。
今回は、単純にセルの値によって書式を指定する Styler.applymapです。
ドキュメントはここ。
「データフレームの値を引数として受け取り、セルに設定したいCSS文字列を返す関数」をapplymapに渡すことで、
DataFrameの書式を設定します。
CSSっぽいな、というのは前々から感じてたのですが、CSSそのものだったんですね。
(CSSとよく似た独自構文を覚えなきゃ使えないのかと思ってました。)
ドキュメントにもそのまま「スタイル設定は、CSSを使用して行われます。」と書いてあるのでちゃんと読んでおけばよかったです。
The styling is accomplished using CSS.
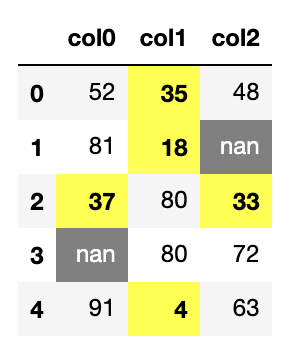
では早速ですが、適当なデータフレームを作ってみて、値が入ってないセル、一定値より小さいセル、
その他のセルで書式を変えて表示してみました。
def cell_style(value):
if value != value:
return "background-color: gray; color: white"
if value <= 40:
return "background-color: yellow; font-weight: bold"
else:
return ""
# 適当なデータフレームを作成
df = pd.DataFrame(
np.random.randint(0, 100, size=(5, 3)),
columns=["col0", "col1", "col2"]
)
df.loc[3, "col0"] = None
df.loc[1, "col2"] = None
df.style.applymap(cell_style)
jupyter notebookで実行したときに表示されるのがこちら。
また、.render()を使ってHTML出力もできます。
スタイルが思ったように適用されてないように感じたら、これを使って確認すると良いそうです。
print(df.style.applymap(cell_style).render())
実行して出力されたHTMLを記事中にそのまま貼り付けたのがこちらです。便利ですね。
| col0 | col1 | col2 | |
|---|---|---|---|
| 0 | 52 | 35 | 48 |
| 1 | 81 | 18 | nan |
| 2 | 37 | 80 | 33 |
| 3 | nan | 80 | 72 |
| 4 | 91 | 4 | 63 |