前回前々回とhyperoptを扱ってきましたが、例があまりにもシンプルだったのでもう少しまともなサンプルを出します。
今回はあらかじめ定義された多変数関数が最大値をとる点を探します。
たった2変数の関数ですが、これ以上変数を増やしても本質的にはやることは変わりません。
きちんと最適解の近くを探していることがわかるように最後に可視化も行います。
例にする関数はこちらです。
$$2*e^{-(x-1)^2-(y-2)^2}+e^{-(x+3)^2-(y+4)^2}$$
点$(1, 2)$からちょっとずれたところで最大値を取りそうな関数ですね。
そして、 点$(-3, -4)$付近にもう一つ山があります。
早速やってみましょう。
import numpy as np
from hyperopt import hp, fmin, tpe, Trials
# 最大値を探したい関数
def f(x, y):
return 2 * np.exp(-(x-1)**2 - (y-2)**2) + np.exp(-(x+3)**2 - (y+4)**2)
# 探索する関数を定義する
def objective(args):
x = args["x"]
y = args["y"]
# 最大値を検索するため、マイナスをつけて符号を反転
return - f(x, y)
# 探索する空間を定義する
space = {
'x': hp.uniform('x', -5, 5),
'y': hp.uniform('y', -5, 5)
}
trials = Trials()
best = fmin(
fn=objective,
space=space,
algo=tpe.suggest,
max_evals=100,
trials=trials,
)
print(best)
# 以下出力
100%|██████████| 100/100 [00:00<00:00, 293.11it/s, best loss: -1.9782848207515258]
{'x': 1.0647780122167085, 'y': 1.9180196819617374}
きちんとそれっぽい点を見つけてきましたね。
これまでの例と違うのは、最小値を探索する関数と、探索する空間が、fminの外側で事前に定義されている点です。
あとは trials オブジェクトの中身を確認し、正解付近を重点的に探索していることを確認しましょう。
import matplotlib.pyplot as plt
X = np.linspace(-5, 5, 100)
Y = np.linspace(-5, 5, 100)
xx, yy = np.meshgrid(X, Y)
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(1, 1, 1)
ax.contour(xx, yy, f(xx, yy))
ax.scatter(trials.vals["x"], trials.vals["y"])
plt.show()
できた図がこちらです。
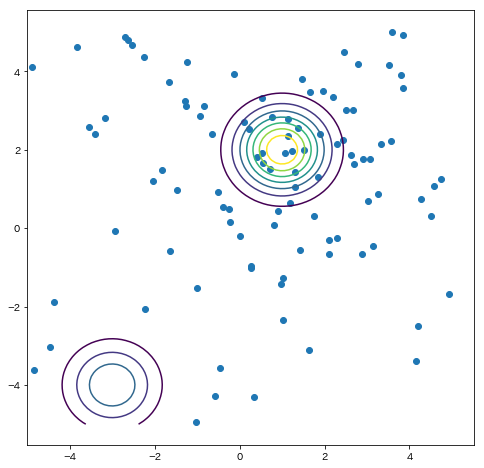
$(-3,-4)$付近はそこそこに、$(1, 2)$付近を重点的に探していることがわかります。