mplfinanceの4記事目です。今後また書くかもしれないけど一旦、連続でmplfinanceを扱うのは今回までにしようと思います。
今回は1枚の画像に複数のグラフを描く方法です。いろんな銘柄を並べて分析する際には必須の技術ですね。
ドキュメントはこちらになります。
参考: mplfinance/subplots.md at master · matplotlib/mplfinance
The Panels Method と、External Axes Method があると書いてありますね。
一つ目のパネルメソッドは特に新しい手法ではなく、以下の記事で紹介した、ローソク足の下にどんどん指標を追加していく方法のことです。
参考: mplfinanceの株価チャートに指標を追加する
ドキュメントにもありますが、この方法はx軸を共有することとか、32個までしか追加できないなどの制限があります。ただ、1銘柄ずつ分析するのであれば手軽で十分な方法だと思います。
今回の記事で紹介するのは、axesを追加していくもう一つの方法です。これはmatplotlibに近い使い方をします。figure(正確には、Mpf_Figure)というオブジェクトを作って、それに対して、subplotを追加し、その中にチャートを書いていきます。
注意しないといけないのは、matplotlibの mpl.figure ではなく、mpfの、mpf.figureを使うことと、plot するときに、ax引数でsubplotを指定することですね。
ドキュメントのサンプルコードでは、次のように4個ハードコーディングした実装が紹介されていますね。
fig = mpf.figure(figsize=(12,9))
<Mpf_Figure size 1200x900 with 0 Axes>
ax1 = fig.add_subplot(2,2,1,style='blueskies')
ax2 = fig.add_subplot(2,2,2,style='yahoo')
s = mpf.make_mpf_style(base_mpl_style='fast',base_mpf_style='nightclouds')
ax3 = fig.add_subplot(2,2,3,style=s)
ax4 = fig.add_subplot(2,2,4,style='starsandstripes')
mpf.plot(df,ax=ax1,axtitle='blueskies',xrotation=15)
mpf.plot(df,type='candle',ax=ax2,axtitle='yahoo',xrotation=15)
mpf.plot(df,ax=ax3,type='candle',axtitle='nightclouds')
mpf.plot(df,type='candle',ax=ax4,axtitle='starsandstripes')
figまぁ、上記のサンプルコードはスタイルの紹介も兼ねてると思いますが、チャートごとにスタイルを変えたいってこともあまりないと思うのでもう少し実用的な例をやってみましょう。
ランダムに選抜した20社のデータを揃えておきました。
print(len(price_df))
# 1680
print(price_df.head(5))
"""
code date open high low close volume
0 1712 2022-06-01 962.0 989.0 957.0 982.0 94300.0
1 1712 2022-06-02 970.0 970.0 958.0 961.0 65400.0
2 1712 2022-06-03 968.0 976.0 955.0 965.0 79400.0
3 1712 2022-06-06 960.0 969.0 950.0 964.0 83100.0
4 1712 2022-06-07 968.0 978.0 962.0 962.0 65700.0
"""
print(price_df["code"].nunique())
# 20また、company_name_dict という辞書に “証券コード”: “企業名” という形でデータがあるとします。ラベルに使います。
この20社のデータを1枚の画像にプロットするコードは次のようになります。
なお、日本語が文字化けするので、前回の記事で紹介した対策をやります。
参考: mplfinanceで日本語文字が表示されない問題について
これは複数チャートを描く場合は、mpf.plot ではなく、 mpf.figure のタイミングでstyleを設定しないといけないという罠がありますので注意してください。
出来上がったコードは次のようになります。
import mplfinance as mpf
import matplotlib.pyplot as plt
font_family = plt.rcParams["font.family"][0] # ファイルで設定したIPAPGothicが入る。
s = mpf.make_mpf_style(
base_mpf_style='default',
rc={"font.family": font_family},
)
# styleはこの時点で設定する。
fig = mpf.figure(figsize=(24,35), style=s)
i = 1
for code, sub_df in price_df.groupby("code"):
ax = fig.add_subplot(5,4,i, title=code + ":" + company_name_dict[code])
mpf.plot(
sub_df,
ax=ax,
type='candle',
)
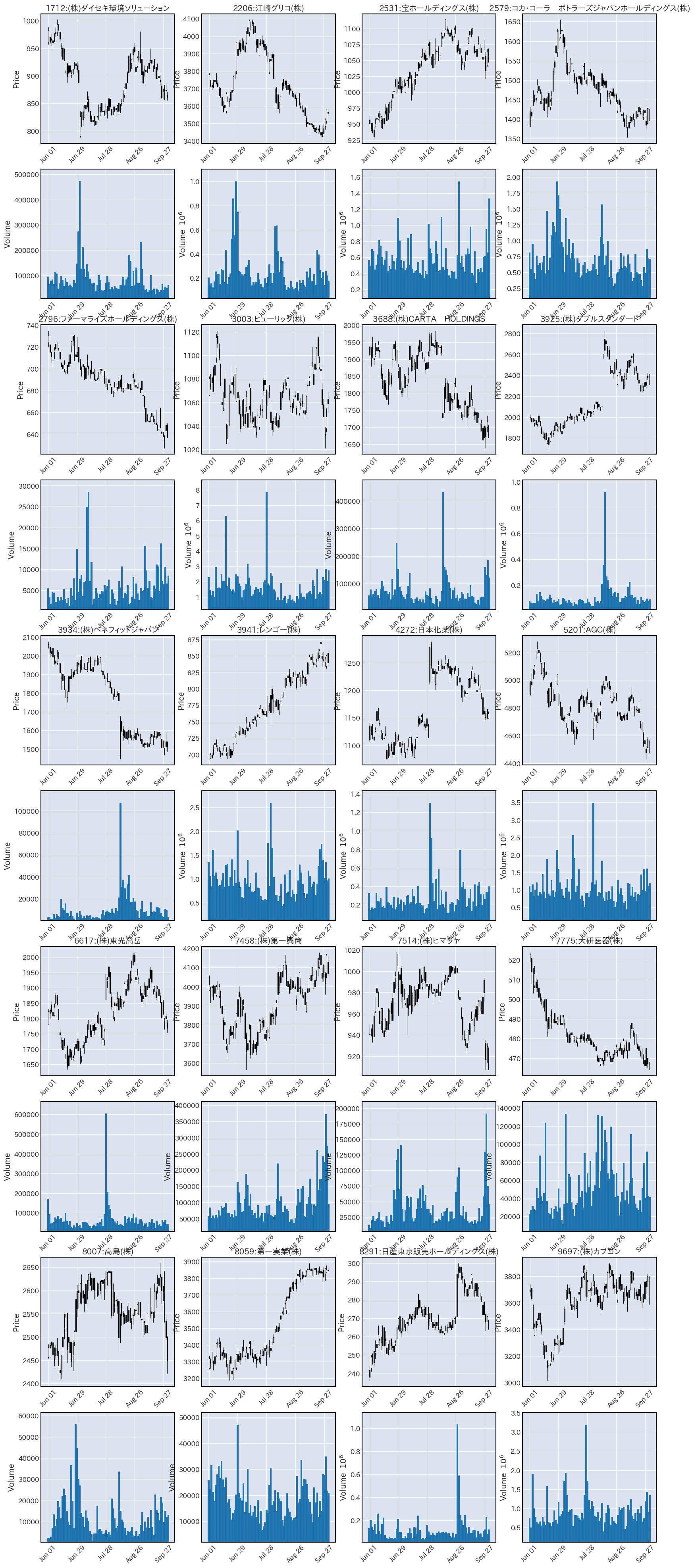
i+=1出力される図がこちらです。
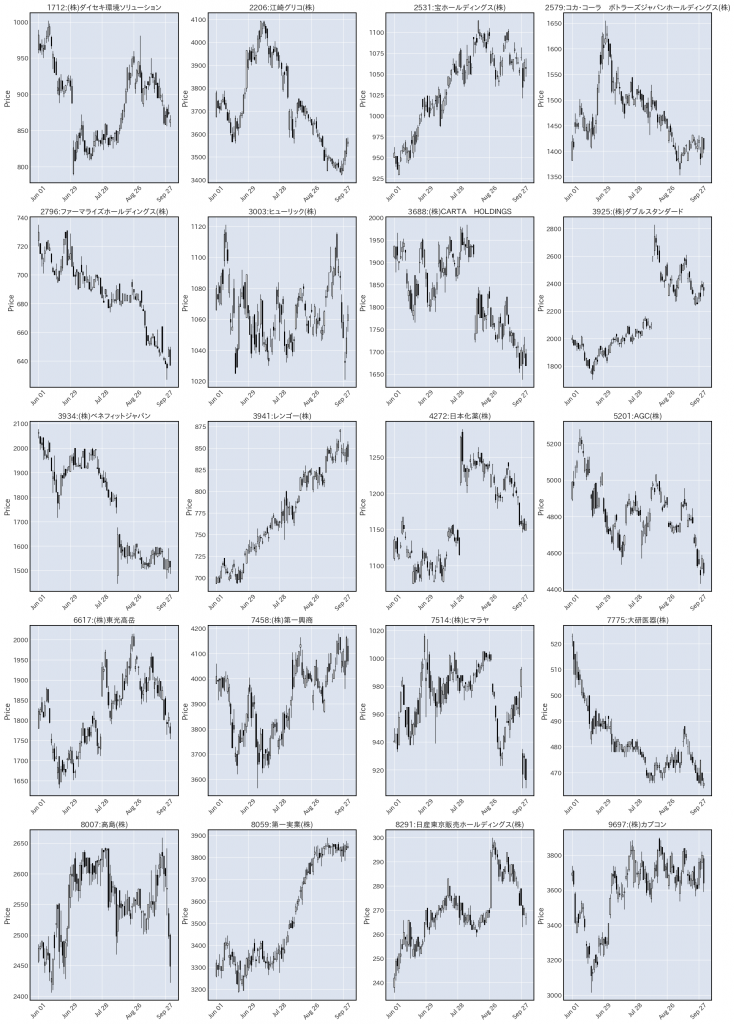
しっかりかけましたね。
パネルメソッドではなくaxesを作成する方法のデメリットとして、volume=True を指定するだけでは出来高のグラフを追加できなくなるということが挙げられます。(エラーになります。)
この手法で出来高も表示したい場合は、出来高用にもaxesを作成し、それをvolume引数に渡す必要があります。
さっとサンプルを作ると次のような感じでしょうか。少し狭くてラベルの重なりが発生したりしていますし、何番目のaxesに四本値と出来高を表示するかの指定がトリッキーなコードになっていますがいったん役目は果たすと思います。
font_family = plt.rcParams["font.family"][0] # ファイルで設定したIPAPGothicが入る。
s = mpf.make_mpf_style(
base_mpf_style='default',
rc={"font.family": font_family},
)
# styleはこの時点で設定する。
fig = mpf.figure(figsize=(20, 50), style=s)
i = 1
for code, sub_df in price_df.groupby("code"):
ax = fig.add_subplot(10,4,i, title=code + ":" + company_name_dict[code])
ax_volume = fig.add_subplot(10,4,i+4)
mpf.plot(
sub_df,
ax=ax,
type='candle',
volume=ax_volume,
)
if i % 4 == 0:
i+=5
else:
i+=1