今回は2変量のVARモデルにしたがうデータから、Pythonを使ってモデルの係数を推定する方法を紹介します。
答え合わせをしたいので、使うデータは特定のVARモデルから生成します。
モデルはいつもの沖本先生の本のP102ページの演習問題から拝借しました。
$$
\left\{\begin{matrix}\
y_{1t} &=& 2+ 0.5 y_{1,t-1}+ 0.4 y_{2,t-1}+\varepsilon_{1t},\\\
y_{2t} &=& -3 + 0.6 y_{1,t-1}+ 0.3 y_{2,t-1}+\varepsilon_{2t}\
\end{matrix}\
\right.\
\left(\begin{matrix}\varepsilon_{1t}\\\varepsilon_{2t}\end{matrix}\right)\sim W.N.(\mathbf{\Sigma})
$$
$$
\Sigma = \left(\begin{matrix}4&1.2\\1.2&1\end{matrix}\right)
$$
まずはデータを生成します。
import numpy as np
import matplotlib.pyplot as plt
mean = np.array([0, 0])
cov = np.array([[4, 1.2], [1.2, 1]])
# 少し長めの系列でデータを生成する。
data = np.zeros([110, 2])
epsilons = np.random.multivariate_normal(mean, cov, size=110)
print(np.cov(epsilons, rowvar=False))
"""
[[3.96508657 1.1917421 ]
[1.1917421 1.01758275]]
"""
for i in range(1, 110):
data[i, 0] = 2 + 0.5*data[i-1, 0] + 0.4*data[i-1, 1] + epsilons[i, 0]
data[i, 1] = -3 + 0.6*data[i-1, 0] + 0.3*data[i-1, 1] + epsilons[i, 1]
# 初めの10項を切り捨てる
data = data[10:]
# data.shape == (100, 2)
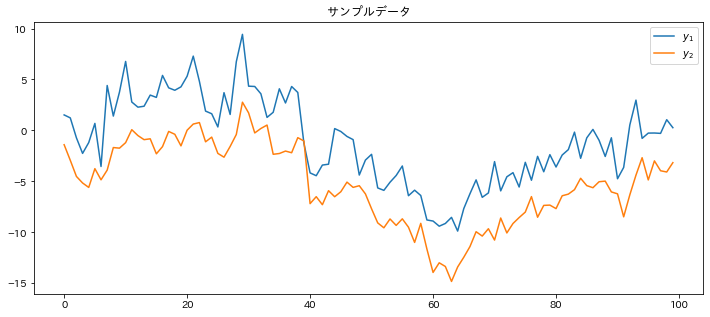
fig = plt.figure(figsize=(12, 5), facecolor="w")
ax = fig.add_subplot(111)
ax.plot(data[:, 0], label="$y_1$")
ax.plot(data[:, 1], label="$y_2$")
ax.set_title("サンプルデータ")
plt.legend()
plt.show()
生成されたデータをプロットしたのがこちら。
さて、いよいよ statsmodelsでVARモデルのパラメーター推定をやりますが、
方法は非常に簡単で、時系列モデルのapiからVARモデルを呼び出してデータを渡し、学習するだけです。
ドキュメント:
Vector Autoregressions tsa.vector_ar
from statsmodels.tsa.api import VAR
model = VAR(data)
result = model.fit(maxlags=1)
print(result.summary())
"""
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Mon, 03, Feb, 2020
Time: 01:10:12
--------------------------------------------------------------------
No. of Equations: 2.00000 BIC: 1.23044
Nobs: 99.0000 HQIC: 1.13680
Log likelihood: -328.071 FPE: 2.92472
AIC: 1.07316 Det(Omega_mle): 2.75521
--------------------------------------------------------------------
Results for equation y1
========================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------
const 1.879511 0.616917 3.047 0.002
L1.y1 0.464346 0.124135 3.741 0.000
L1.y2 0.462511 0.132200 3.499 0.000
========================================================================
Results for equation y2
========================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------
const -2.683660 0.305923 -8.772 0.000
L1.y1 0.561468 0.061557 9.121 0.000
L1.y2 0.385671 0.065556 5.883 0.000
========================================================================
Correlation matrix of residuals
y1 y2
y1 1.000000 0.583971
y2 0.583971 1.000000
"""
今回はモデルの形が事前にわかっているので、 maxlags=1 としましたが、 ここを少し大きめの値にしておけば自動的にlagの値を選んでくれます。
選び方は 引数”ic”で指定できます。 (未指定ならAIC)
ic : {‘aic’, ‘fpe’, ‘hqic’, ‘bic’, None}
Information criterion to use for VAR order selection.
aic : Akaike
fpe : Final prediction error
hqic : Hannan-Quinn
bic : Bayesian a.k.a. Schwarz
さて、結果の係数ですが、summaryを見ると大体次の値になっています。(四捨五入しました)
$$
\left\{\begin{matrix}\
y_{1t} &=& 1.89+ 0.46 y_{1,t-1}+ 0.46 y_{2,t-1}\\\
y_{2t} &=& -2.68 + 0.56 y_{1,t-1}+ 0.39 y_{2,t-1}\
\end{matrix}\
\right.\
$$
とても正確というわけではありませんが、概ね正しく推定できていそうです。