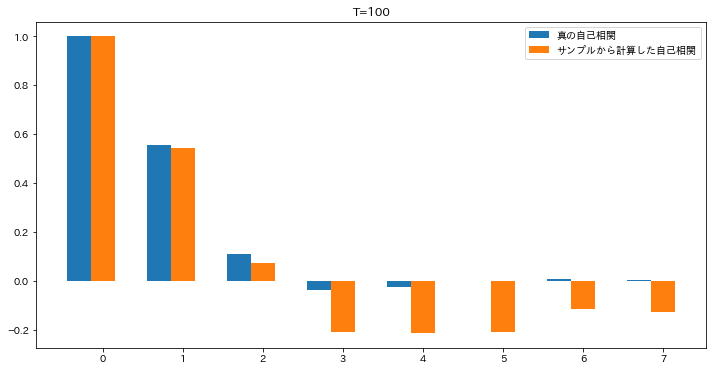
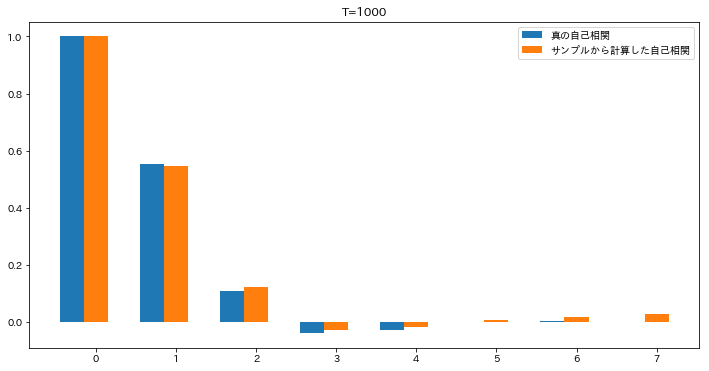
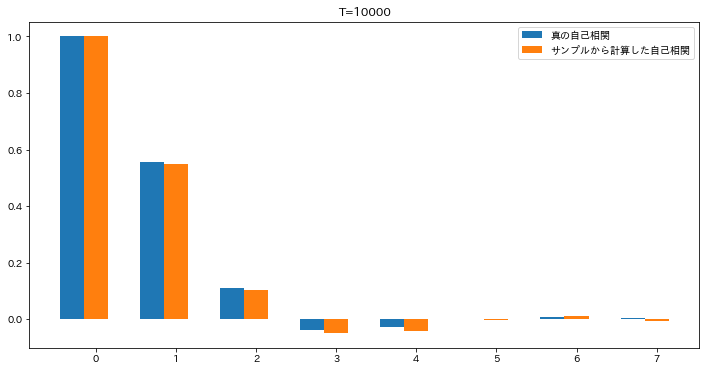
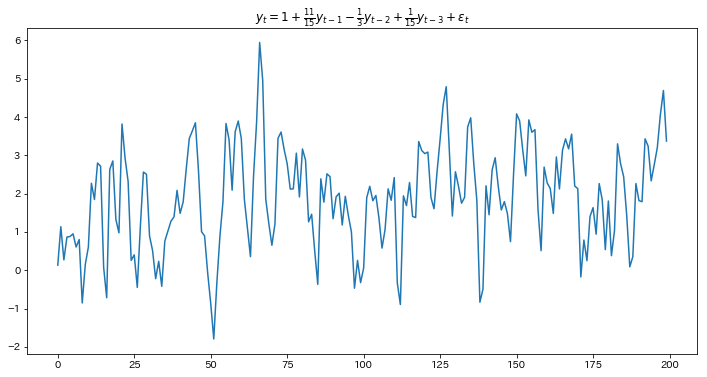
今日もまた沖本本からMA過程の話題です。
本題に入る前にAR過程の復習ですが、このブログでも紹介した通り、
AR過程は定常になるとは限らず、各種の性質については、定常AR過程なら、という前提がついていました。
参考:自己回帰過程の定義と定常になる条件、定常自己回帰過程の性質
その一方で、MA過程については常に定常でなのでとても扱いやすいように見えます。
しかし、MA過程には同一の期待値と、同一の自己相関構造を持つ異なるMA過程が複数存在するという問題があります。
一般に、同一の期待値と自己相関構造を持つMA(q)過程は$2^q$個存在するらしいです。
本に、MA(1)の例が載っているので、このブログではMA(4)あたりに対して、この$2^4=16$個がそうだ!って例を見つけて描きたかったのですが、
挫折したので本に載ってるMA(1)に対する例を紹介します。
それは
$$
\begin{eqnarray}
y_t = \varepsilon_t +\theta\varepsilon_{t-1} , \varepsilon_t \sim W.N.(\sigma^2)
\end{eqnarray}
$$
と、
$$
\begin{eqnarray}
y_t = \tilde{\varepsilon}_t+\frac{1}{\theta}\tilde{\varepsilon}_{t-1}, \tilde{\varepsilon}_t \sim W.N.(\theta^2\sigma^2)
\end{eqnarray}
$$
です。
これの期待値や自己相関を 移動平均過程の定義と性質 で紹介した式に沿って計算すると、一致することを確認できます。
この時、$2^q$個のMA(q)過程の中からどれを採用するかの基準が必要になりますが、
そのために一つの基準になるのがMA過程の反転可能性(invertibility)です。
MA(q)過程が反転可能(invertible)とは、そのMA(q)過程をAR($\infty$)過程に書きなおせることです。
例えば、$|\theta|<1$であれば、 $$ y_t = \varepsilon_t + \theta\varepsilon_{t-1} $$ は $$ y_t = -\sum_{k=1}^{\infty}(-\theta)^ky_{t-k}+\varepsilon_t $$ と書き直せます。 このMA(1)の例も沖本先生の本からです。 (MA(2)の例を紹介しようと計算を頑張っていたのですが思ったより複雑になったので本の例をそのまま。) 一般のMA(q)過程の反転可能性については、AR過程の定常条件とよく似ています。 次のMA特性方程式を調べることで確認できます。 $$ 1+\theta_1z+\theta_2z^2+\cdots+\theta_qz^q=0. $$ このMA特性方程式の全ての解の絶対値が1より大きければMA過程は反転可能になります。 この時、撹乱項$\varepsilon_t$は、$y_t$を過去の値から予測した時の予測誤差と解釈できます。 昔、別の本で移動平均過程を勉強した時、いきなり移動平均もでるは誤差項による回帰だと書かれていて全く理解できなったのですが、 ようやく理解できました。 沖本先生の本だと、反転可能なものの唯一性等の証明が載っていない(そして自分で証明しようともしたが上手くいっていない)ので、 何かの折に他の文献にも当たってみようと思います。