今回もkerasの学習率改善のコールバックの話です。
LearningRateScheduler を使って、エポックごとの学習率を変えられることを紹介しましたが、
実際、学習をやってみる前に最適な学習率の変化の計画を立てておくことは非常に困難です。
最初は大きめの値でどんどん学習して、それではうまくいかなくなった段階で徐々に下げるということをやりたくなります。
そして、 kerasにはそのためのコールバックの、ReduceLROnPlateau というのが用意されています。
監視する評価値、何エポック改善しなかったら学習率を落とすか、その変化の割合、最小値などを指定すると、
学習の進みに応じて調整してくれます。
さっそく適当なモデルで試してみましょう。
(今回は着目するのが学習率の変化なので、下のコードのモデルは対して良いものでもないことをご了承ください。)
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ReduceLROnPlateau
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
# データの読み込み
(data_train, target_train), (data_test, target_test) = fashion_mnist.load_data()
# Conv2D の inputに合わせて変形
X_train = data_train.reshape(-1, 28, 28, 1)
X_test = data_test.reshape(-1, 28, 28, 1)
# 特徴量を0~1に正規化する
X_train = X_train / 255
X_test = X_test / 255
# ラベルを1 hot 表現に変換
y_train = to_categorical(target_train, 10)
y_test = to_categorical(target_test, 10)
# lr に少し大きめの値を設定しておく (デフォルトは lr =0.001)
adam = Adam(lr=0.01)
# モデルの構築
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3),
activation='relu',
input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(
loss="categorical_crossentropy",
optimizer=adam,
metrics=['acc']
)
print(model.summary())
"""
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 13, 13, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 11, 11, 32) 4640
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 5, 5, 32) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 800) 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 51264
_________________________________________________________________
dropout_7 (Dropout) (None, 64) 0
_________________________________________________________________
dense_7 (Dense) (None, 10) 650
=================================================================
Total params: 56,714
Trainable params: 56,714
Non-trainable params: 0
_________________________________________________________________
"""
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=10,
)
# val_lossの改善が2エポック見られなかったら、学習率を0.5倍する。
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=2,
min_lr=0.0001
)
history = model.fit(X_train, y_train,
batch_size=128,
epochs=50,
verbose=2,
validation_data=(X_test, y_test),
callbacks=[early_stopping, reduce_lr],
)
"""
(途中は省略。以下は最終的な結果)
Epoch 26/50
60000/60000 - 12s - loss: 0.2263 - acc: 0.9138 - val_loss: 0.3177 - val_acc: 0.8998
"""
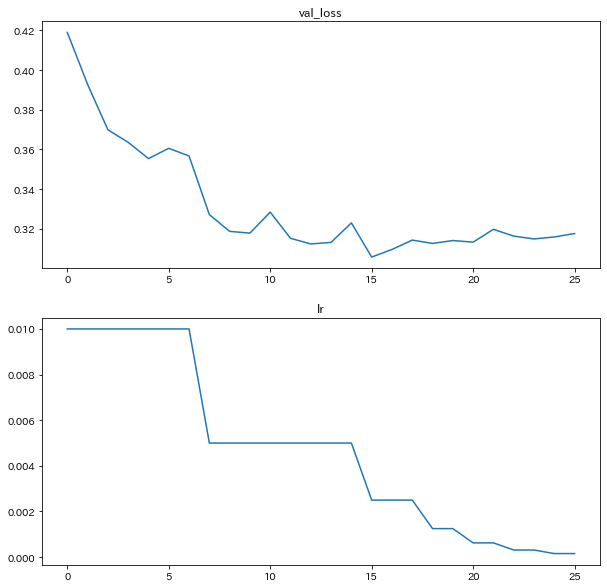
さて、学習が完了したことで、history に結果が入りましたので、 監視していた val_loss と学習率 lrをみてみましょう。
# val_loss と lr を可視化
fig = plt.figure(figsize=(10, 10), facecolor="w")
ax = fig.add_subplot(2, 1, 1)
ax.set_title("val_loss")
ax.plot(range(len(history.history["val_loss"])), history.history["val_loss"])
ax = fig.add_subplot(2, 1, 2)
ax.set_title("lr")
ax.plot(range(len(history.history["lr"])), history.history["lr"])
plt.show()
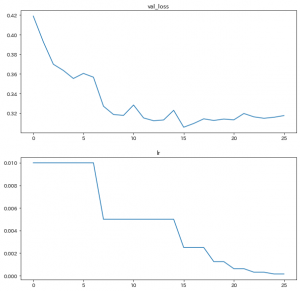
学習率が段階的に半減していっているのが確認できますね・