前回の記事に続いてカーネル密度推定の話です。
参考: カーネル密度推定法の紹介
前の記事では数式に沿って実装するため、numpyで書きましたが、普段の利用では、SciPyにクラスが実装されているのでこれを使えます。
参考: scipy.stats.gaussian_kde
クラス名から分かる通り、カーネルはガウスカーネルがあらかじめ指定されており、他の関数は使えません。
実際のところ、ガウスカーネル以外が使えなくて困ることは滅多にないでしょう。
使い方ですが、 インスタンスを作るときに、データセットを渡すだけで完了します。
とてもありがたいことに、バンド幅の指定が要りません。
デフォルトでは Scottのルールと呼ばれる方法で決定されます。
bw_methodという引数で指定することで、もっと直接的な指定や、Silvermanのルールを使うことも可能です。
ScottのルールとSilvermanのルールがそれぞれ具体的にどの様にバンド幅を決めているのかは後日のブログで紹介するとして、
とりあえず、正規分布から生成したデータで使ってみましょう。
from scipy.stats import gaussian_kde
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
# 50件のデータをサンプリング
data = norm(loc=2, scale=2).rvs(50)
# グラフ描写のため真の確率密度関数の値を取得しておく
xticks = np.linspace(-5, 9, 141)
pdf_values = norm(loc=2, scale=2).pdf(xticks)
# カーネル密度推定
kde = gaussian_kde(data)
# evaluate には pdfというエイリアスがあるのでそちらでも可
estimated_value = kde.evaluate(xticks)
# 可視化
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(111)
ax.plot(xticks, pdf_values, label="真の分布")
ax.plot(xticks, estimated_value, label="推定値", linestyle="--")
# 標本データ
for x in data:
ax.vlines(x, ymin=0, ymax=0.01, alpha=0.5)
ax.set_ylim((0, 0.25))
ax.legend()
plt.show()
出力結果がこちらです。
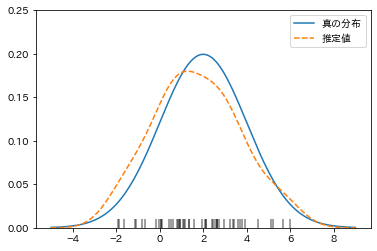
とても手軽に良い推定が得られていますね。
ちなみに、推定してくれたバンド幅ですが、covariance という属性にその情報を持っています。
# バンド幅の確認 (hの2乗なので注意)
print(kde.covariance)
# [[0.79905207]]
多次元にも対応するため、分散共分散行列の形でデータを持てる様になっています。
今回は1次元データなので、ちょっと面倒ですが、無駄に2次元配列になってる中から要素を持ってくる必要があります。
varianceなので、この値は分散、前回の記事のバンド幅は標準偏差なので、平方根を取る必要があることも注意です。
せっかく推定してくれたバンド幅が取れるので、前回スクラッチで描いたコードの推定値と結果が一致することも見ておきましょう。
前回の記事のコピーだと、関数名が重複してしまって面倒なので適当に、my_kdeにリネームしました。
# ガウスカーネル
def gaussian_kernel(u):
return(np.exp(-(u**2)/2)/np.sqrt(2*np.pi))
# ガウスカーネルを用いたカーネル密度推定
def my_kde(x, h, dataset):
return sum([gaussian_kernel((x-d)/h) for d in dataset])/(len(dataset)*h)
# バンド幅の取得
h = np.sqrt(kde.covariance[0][0])
# 可視化
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(111)
ax.plot(xticks, pdf_values, label="真の分布")
ax.plot(xticks, kde.evaluate(xticks), label="scipy", linestyle="--")
ax.plot(xticks, my_kde(xticks, h, data), label="スクラッチ", linestyle=":")
ax.legend()
plt.show()
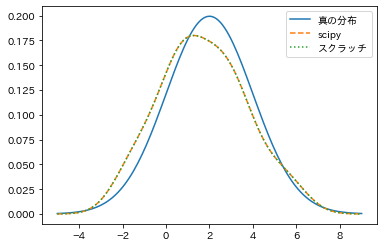
SciPy で出した結果と、スクラッチで書いてるやつの結果が(一致してることの確認なので)重なってしまっていて、見にくいですが、
一応線の種類を変えてあるので、よく見るとしっかり同じところに線が引かれているのが分かります。