要するに、seasonal_decomposeメソッドの使い方の紹介記事です。これもとっくに書いたと思っていたら書いてなかったのでまとめておきます。この記事では季節分解の概要の説明とライブラリの使い方を紹介します。そして、これの次の記事でstatsumodelsがどのような実装で季節分解を行っているのかを解説する予定です。
参考: statsmodels.tsa.seasonal.seasonal_decompose — statsmodels
現実の時系列データは、何かしらの季節性を持っていることが多くあります。季節って単語で言うと、春夏秋冬や、何月、といった粒度のものが想像されやすいですが、1週間の中で見ても曜日の傾向とか、1日の中でも時間帯別の違いなどがあります。
時系列データからこの季節に依存する部分を取り出し、季節成分と、トレンド成分、そして残差へと分解する手法が今回紹介する季節分解です。Wikipediaでは季節調整と書いてあります。また、基本成分など、別の用語を使ってる人もいるようです。(どれが一番メジャーなんだろう。)
定式化しておくと、元の時系列データ$Y_{t}$をトレンド成分$T_t$と季節成分$S_t$、そして残差$e_t$を用いて、
$$
Y_t = T_t + S_t + e_t
$$
と分解することを目指します。上記のは加法モデルと呼ばれる形で、和の代わりに積で分解する乗法モデル、
$$
Y_t = T_t * S_t * e_t
$$
もあります。
季節成分$S_t$は周期性を持っているので、その周期を$p$とすると、$S_{t}=S_{t+p}$を満たします。
具体的に例を見るのが早いと思うので、やっていきましょう。サンプルとして用意したデータはこのブログのpv数です。インデックスを日付けにしていますが、こうしておくとライブラリでplotしたときにx軸に日付が表示されるで便利です。ただ、通常の通し番号のindexでも動きます。
# データ件数
print(len(df))
# 140
# 2週間分のデータ
print(df.tail(14))
"""
pv
date
2022-10-24 2022
2022-10-25 2140
2022-10-26 2150
2022-10-27 1983
2022-10-28 1783
2022-10-29 847
2022-10-30 793
2022-10-31 1991
2022-11-01 2104
2022-11-02 1939
2022-11-03 1022
2022-11-04 1788
2022-11-05 830
2022-11-06 910
"""最後に元のデータのグラフも出るので可視化しませんが、上の例見ても10/29,30や11/5,6など土日にpvが減っていて逆に平日多く、曜日ごと、つまり7日周期がありそうな想像がつきます。詳細省略しますが、自己相関等で評価してもはっきりとその傾向が出ます。
では、やってみましょう。まず、分解自体はライブラリにデータを渡して周期を指定するだけです。
from statsmodels import api as sm
decompose_result = sm.tsa.seasonal_decompose(
df["pv"],
period=7, # 周期を指定する
)結果は以下のプロパティに格納されています。DecomposeResultというデータ型で、ドキュメントはこちらです。
参考: statsmodels.tsa.seasonal.DecomposeResult — statsmodels
順番に表示していきます。
# データの数。
decompose_result.nobs[0]
# 140
# 元のデータ
print(decompose_result.observed[: 10])
"""
date
2022-06-20 1703.0
2022-06-21 1758.0
2022-06-22 1732.0
2022-06-23 1744.0
2022-06-24 1587.0
2022-06-25 654.0
2022-06-26 691.0
2022-06-27 1695.0
2022-06-28 1740.0
2022-06-29 1655.0
Name: pv, dtype: float64
"""
# トレンド成分
print(decompose_result.trend[: 10])
"""
date
2022-06-20 NaN
2022-06-21 NaN
2022-06-22 NaN
2022-06-23 1409.857143
2022-06-24 1408.714286
2022-06-25 1406.142857
2022-06-26 1395.142857
2022-06-27 1370.714286
2022-06-28 1345.285714
2022-06-29 1347.142857
Name: trend, dtype: float64
"""
# 季節成分
print(decompose_result.seasonal[: 14])
"""
date
2022-06-20 245.450913
2022-06-21 399.887003
2022-06-22 343.774221
2022-06-23 259.738131
2022-06-24 142.180236
2022-06-25 -718.052846
2022-06-26 -672.977658
2022-06-27 245.450913
2022-06-28 399.887003
2022-06-29 343.774221
2022-06-30 259.738131
2022-07-01 142.180236
2022-07-02 -718.052846
2022-07-03 -672.977658
Name: seasonal, dtype: float64
"""
# 残差
print(decompose_result.resid[: 10])
"""
date
2022-06-20 NaN
2022-06-21 NaN
2022-06-22 NaN
2022-06-23 74.404726
2022-06-24 36.105478
2022-06-25 -34.090011
2022-06-26 -31.165199
2022-06-27 78.834801
2022-06-28 -5.172718
2022-06-29 -35.917078
Name: resid, dtype: float64
"""トレンド成分が最初の3項NaNになっているのは、アルゴリズムの都合によるものです。その日を中心とする前後で合計7日(周期分)のデータで移動平均をとっており、要するに、過去の3日、当日、次の3日間、の合計7日分のデータがないと計算できないので最初の3日と、表示していませんが最後の3日間はNaNになっています。この辺の挙動は推定時の引数で調整できます。
次に季節成分は14日分printしましたが、最初の7日間の値が繰り返されて次の7日間でも表示されているのがわかると思います。ずっとこの繰り返しです。
残差は元のデータからトレンド成分と季節成分を引いたものになります。トレンド成分や季節成分に比べて値が小さくなっていて、今回のデータではトレンドと季節である程度分解が綺麗に行えたと考えられます。
さて、データが取れたのでこれを使えばmatplotlib等で可視化できるのですが、大変ありがたいことにこのDecomposeResultが可視化のメソッドを持っています。
少し不便なところは、そのplotメソッドがfigsizeとかaxとかの引数を受け取ってくれないので、微調整とかしにくいのですよね。
個人的な感想ですが、デフォルトでは少しグラフが小さいのでrcParamsを事前に変更してデフォルトのfigsizeを大きくし、それで可視化します。
import matplotlib.pyplot as plt
# 注: DecomposeResult.plot()を実行するだけなら matplotlibのimportは不要。
# 今回画像サイズを変えるためにインポートする
# figure.figsizeの元の設定を退避しておく
figsize_backup = plt.rcParams["figure.figsize"]
# 少し大きめの値を設定
plt.rcParams["figure.figsize"] = [10, 8]
# 可視化
decompose_result.plot()
plt.show()
# 設定を元に戻す
plt.rcParams["figure.figsize"] = figsize_backupこれで出力される画像が以下です。
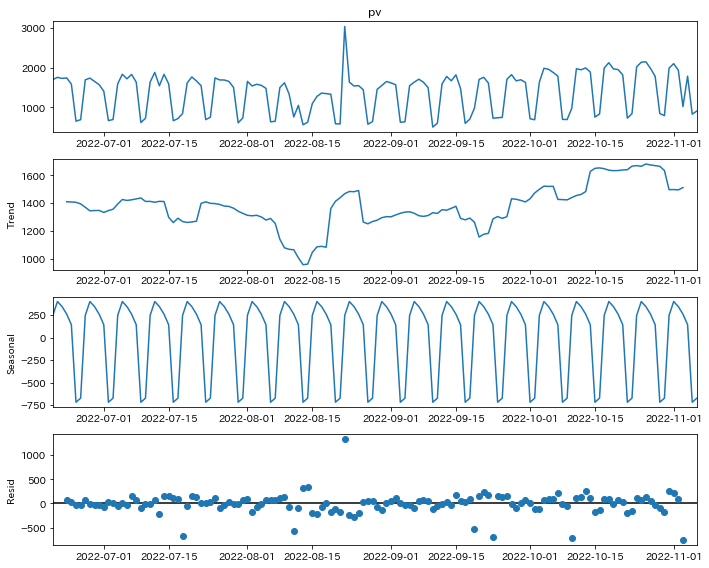
一番上が元のpvです。冒頭に書いた通り、生データそのまま見ても周期性が明らかですね。
トレンド成分を見ていくと、お盆の時期にアクセスが減っていますが、その後順調にアクセスが伸びていることがわかりますね。
残差で見ると大きくアクセスが減っているのはそれぞれ祝日に対応しています。
8月に1日だけ異常にアクセス伸びた日がありますがこれは謎です。
説明や例をいろいろ書いてきたので長くなりましたが、基本的には、seasonal_decompose()で分解して、plot()で可視化してそれで完成という超お手軽ライブラリなので、時系列データが手元にあったらとりあえず試す、くらいの温度感で使っていけると思います。
最後に、seasonal_decompose にオプション的な引数が複数あるので使いそうなものを説明してきます。
まず、model= は、 “additive”,”multiplicative” の一方をとり、加法的なモデルか乗法的なモデルを切り替えることができます。デフォルトは、”additive”です。
two_sided= は True/Falseの値をとり、デフォルトはTrueです。これはトレンド成分の抽出方法を指定するもので、Trueの時は、その日を挟むように前後の日付から抽出しますが、Falseの場合は、その日以前の値から算出されます。True or False で並行移動するイメージです。
次回の記事で詳細書こうと思いますが、周期が偶数か奇数かで微妙に異なる挙動をするので注意が必要です。
extrapolate_trend= はトレンド成分の最初と最後の欠損値を補完するための引数です。1以上の値を渡しておくと、その件数のデータを使って最小二乗法を使って線形回帰してトレンドを延長し、NaNをなくしてくれます。使う場合はその回帰が妥当かどうか慎重にみて使う必要がありそうです。