データフレームの書式設定シリーズの最後の記事です。
今回は背景にセルの値の大きさを表す棒グラフを表示します。
これ、地味に便利です。
ドキュメントはこちら。
使い方は簡単で、df.style.bar()を呼び出すだけです。
オプションも色々指定子できますので、いくつか設定してやってみます。
# 適当なデータフレームを作成
df = pd.DataFrame(
np.random.randint(-100, 100, size=(10, 4)),
columns=["col0", "col1", "col2", "col3"]
)
df.style.bar(
align="mid",
width=90,
axis=None,
color=['#d65f5f', '#5fba7d']
)
出力結果がこちら。
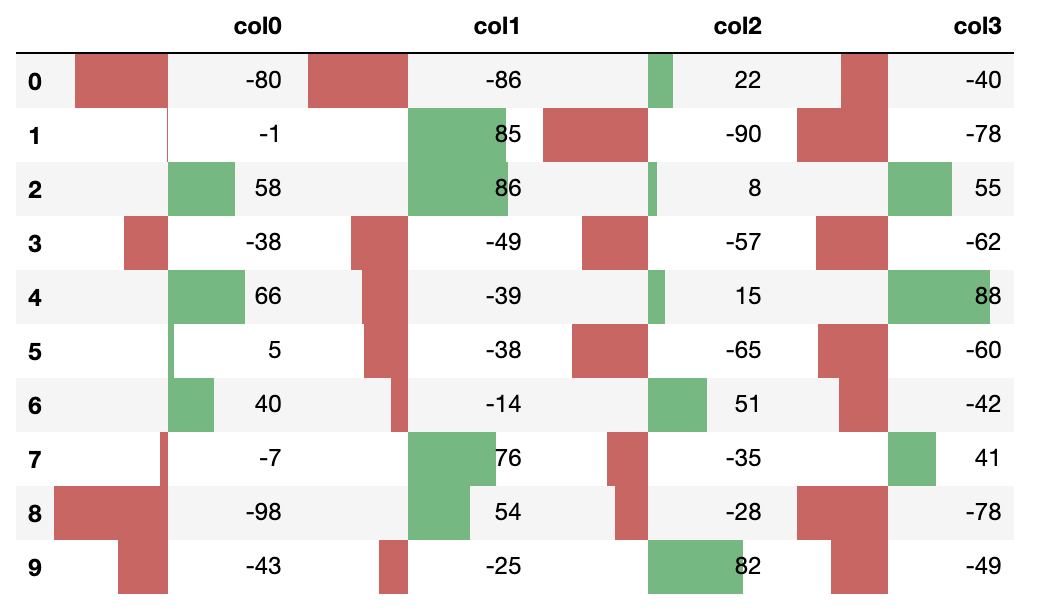
引数をいくつか説明しておきます。
まず align。 以下の3種類の値のどれかを取ります。
- left
- 値が最小のセルの値が左端。デフォルト。
- zero
- ゼロがセルの中心
- mid
- 最大値と最小値の平均か、もし正の数と負の数を両方含む場合は0が中心。
次に width は0〜100の値を取り、棒グラフの最大長がセルの何%を締めるかを表します。
colerは棒グラフの色です。文字列を一つ渡せば全てその色、配列にして2つ渡せばそれぞれ負の値の時と正の値の時の色です。
axis は最大最小値の基準が列方向(0)、行方向(1)、テーブル全体(None)のどれかを表します。
例では使っていませんが、vmin, vmax で最小値、最大値を指定することもできます。
外れ値があるような時は便利です。