matplotlibでは、 matplotlib.axes.Axes.text メソッドを指定して、グラフ中にテキストを挿入できます。
このとき、通常は、 ax.text({x座標}, {y座標}, {挿入したいテキスト}) という構文でテキストが入れられます。
ここで言う、 x座標/ y座標は それぞれx軸、y軸に対応した座標になります。当然ですね。
散布図の点や、グラフの頂点に文章を補足するときはとてもありがたい仕様ですが、
その反面、グラフの左上の方、とか中央といった、グラフの中の特定の場所にテキストを入れたい場合はちょと不便です。
それは、グラフの枠の左上や中央の座標が何になるか非自明だからです。
このニーズに対応して、x軸、y軸の座標ではなく、グラフ内部の位置でテキストの位置を指定できることがわかったので紹介します。
ドキュメントの Examples のところに 例があるのですが、transform=ax.transAxesを指定すると、ax.textのx座標、y座標はx軸y軸とは関係なくなり、
グラフの枠の左下を(0, 0), 右上を(1, 1)とする相対座標に変わります。
これを使って、グラフのすみの方や中央に簡単にテキストを置けます。
ちなみに、デフォルトでは、指定した座標の位置に、テキストの左下が当たるように配置されます。
これは、縦位置は verticalalignment{‘center’, ‘top’, ‘bottom’, ‘baseline'(デフォルト), ‘center_baseline’}、
横位置はhorizontalalignment{‘center’, ‘right’, ‘left'(デフォルト)} という引数で変更することができます。
引数名が長いので、それぞれ、va, ha というエイリアスを用意してくれています。
これらの引数は、 transform=ax.transAxes を指定しない時も同じように使えるので覚えておきましょう。
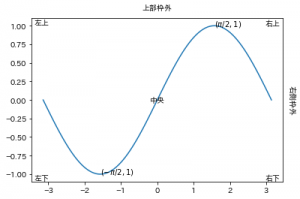
あまり面白い例でなくて恐縮ですが、色々パターンを試したコードとその出力を置いておきます。
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-np.pi, np.pi, 101)
y = np.sin(x)
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(1, 1, 1)
ax.plot(x, y)
# 通常は、指定した座標の位置にテキストが挿入される
ax.text(np.pi/2, 1, "$(\pi/2, 1)$")
ax.text(-np.pi/2, -1, "$(-\pi/2, 1)$")
# transform=ax.transAxes を指定すると、図形の枠を基準にした位置にテキストが挿入される
ax.text(0.01, 0.01, "左下", transform=ax.transAxes)
ax.text(0.01, 0.99, "左上", verticalalignment='top', transform=ax.transAxes)
ax.text(0.99, 0.01, "右下", horizontalalignment='right', transform=ax.transAxes)
ax.text(0.99, 0.99, "右上", va='top', ha='right', transform=ax.transAxes)
ax.text(0.5, 0.5, "中央", va='center', ha='center', transform=ax.transAxes)
# 0 ~ 1 の範囲を超えるとグラフの外にテキストを配置できる
ax.text(0.5, 1.05, "上部枠外", ha='center', transform=ax.transAxes)
ax.text(1.02, 0.5, "右側枠外", va='center', transform=ax.transAxes, rotation=270)
plt.show()
出力はこちらです。
transform 引数に他にどんな値を設定しうるのか探したところ、以下のページが見つかりました。
参考: Transformations Tutorial
ax.transData がデフォルトのデータにしがたった座標軸みたいですね。
ax.transAxes の他にも、fig.transFigureやfig.dpi_scale_trans を使って、図全体の中での相対位置で
テキストを配置することもできるようです。
fig.transFigure のほうが、左下が(0, 0)、右上が(1, 1) となる座標で、
fig.dpi_scale_trans はピクセル数を使った具体的な座標指定です。