個人的な好みの話ですが、僕は割合の可視化は円グラフより100%積み上げ棒グラフの方が好みです。前職時代はこの種の可視化はもっぱらTableauで描いていたのですが転職して使えなくなってしまったので、Pythonでサクッと描ける方法をメモしておきます。
最初、matplotlibのbarやbarhでbottomやleftを逐一指定してカテゴリごとに描いていく方法を紹介しようと思っていたのですが、pandas.DataFrameのメソッドを使った方が簡単だったのでそちらを先に紹介します。
データの準備
サンプルデータが必要なので適当にDataFrameを作ります。地域ごとに、どの製品が売れているか、みたいなイメージのデータです。
import pandas as pd
data = {
'製品A': [20, 30, 50],
'製品B': [60, 70, 40],
'製品C': [20, 0, 10]
}
df = pd.DataFrame(data, index=["地域1", "地域2", "地域3"])
print(df)
"""
製品A 製品B 製品C
地域1 20 60 20
地域2 30 70 0
地域3 50 40 10
"""こちらを地域別に、売れている製品の内訳を可視化していきます。
これも個人的な好みの話ですが、棒グラフは縦向きではなく横向きにします。(ラベルが日本語だとその方が自然な結果になりやすいからです。)
シンプルにやるには、jupyter環境であれば以下のコードだけで目的のグラフが表示されます。
# データの正規化
df_normalized = df.div(df.sum(axis=1), axis=0)
# 横向きの積み上げ棒グラフの描画
df_normalized.plot(kind='barh', stacked=True)少し脇道に逸れますが、みなさん、この行ごとに正規化するdf.div(df.sum(axis=1), axis=0) ってやり方ご存知でした?昔、「Pandasのデータを割合に変換する」って記事を書いたときは知らなかった方法でした。このときは転置して列ごとに正規化してもう一回転置するという手順を踏んでましたね。
記事の本題に戻ると、plotメソッドのstackedっていう引数をTrueにしておくと棒グラフを積み上げて表示してくれるため目的のグラフになります。
参考: pandas.DataFrame.plot.barh — pandas 2.1.3 documentation
ただ、これで出力すると、グラフの棒の並び順が上から順に地域3, 地域2, 地域1 となり、ちょっと嫌なのと、あとラベル等のカスタマイズも行えた方が良いと思うのでもう少し丁寧なコードも紹介しておきます。(こだわりなければさっきの2行で十分です。)
import matplotlib.pyplot as plt
# データの正規化
df_normalized = df.div(df.sum(axis=1), axis=0)
# 行の順序を逆にする
df_normalized = df_normalized.iloc[::-1]
# 横向きの積み上げ棒グラフの描画
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(111)
df_normalized.plot(kind="barh", stacked=True, ax=ax)
# タイトルとラベルの設定(任意)
ax.set_title("地域別の販売製品割合")
ax.set_ylabel("地域")
ax.set_xlabel("割合")
plt.show()出来上がりがこちら。
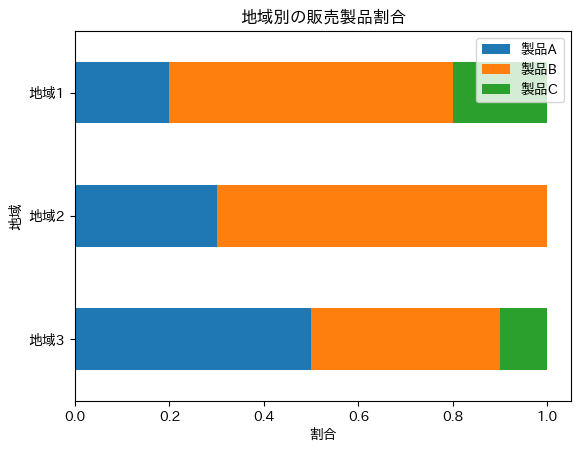


はい、サクッとできましたね。
ちなみに、pandasのplotメソッドを使わない場合は棒グラフの各色の部分の左端の位置を指定しながら順番に描くため、次のコードになります。
import numpy as np
# 積み上げ棒グラフを作成するための基準位置
left = np.zeros(len(df_normalized))
fig = plt.figure(facecolor="w")
ax = fig.add_subplot(111)
# 各カテゴリごとにバーを追加
for column in df_normalized.columns:
ax.barh(
df_normalized.index,
df_normalized[column],
left=left,
label=column,
height=0.5
)
left += df_normalized[column]
# タイトルとラベルの設定
ax.set_title("地域別の販売製品割合")
ax.set_ylabel('地域')
ax.set_xlabel('割合')
# 凡例の表示
ax.legend()
plt.show()明らかに面倒なコードでしたね。pandasがいい感じに調整してくれていた、棒の太さ(横向きなので今回の例では縦幅)なども自分で調整する必要があります。
Pythonでコーディングしてるのであれば大抵の場合は元データはDataFrameになっているでしょうし、もしそうでなくても変換は容易なので、Pandasに頼った方を採用しましょう。