kerasにはscikit-learnと同じように、いつくかのサンプルデータが付属しています。
その中の一つがMNISTという28*28ピクセルの手書き数字文字のデータです。
scikit-learn にも digits という手書き数字のサンプルデータがありますが、こちらは8*8ピクセルの結構データ量の小さいデータです。
ライブラリの使い方を紹介する上ではこれで問題がないのでよく使っていますが、深層学習をつかずとも十分に判別できてしまうのが短所です。
(このブログの過去の記事でも使ってきたのはこちらです。)
せっかくディープラーニングを試すのであればこちらを使った方がいいと思うので、使い方を紹介します。
ドキュメントはここ。
MNIST database of handwritten digits
早速ですが読み込み方法です。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
インポートしてloadすれば良いというのは scikit-learnのサンプルデータと同じですが、
load_dataの戻り値が少し特徴的です。
長さ2のタプル2個を値に持つタプルを返してきます。
これを受け取るために、上記のような書き方をします。
変数に格納された配列の次元数を見ると次のようになります。
print(x_train.shape) # (60000, 28, 28)
print(y_train.shape) # (60000,)
print(x_test.shape) # (10000, 28, 28)
print(y_test.shape) # (10000,)
x_train などの中身を見れば、ピクセルごとの濃淡として画像データが入っていることがわかるのですが、
せっかくの画像データなので、画像として可視化してみましょう。
matplotlibのimshow という関数を使うと便利です。
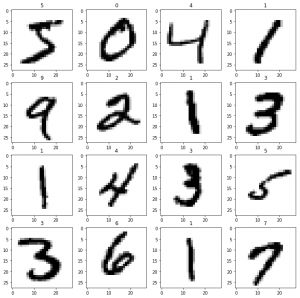
最初の16データを可視化したのが次のコードです。
デフォルトの配色はイマイチだったので、文字らしく白背景に黒文字にしました。
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12, 12))
for i in range(16):
ax = fig.add_subplot(4, 4, i+1, title=str(y_train[i]))
ax.imshow(x_train[i], cmap="gray_r")
plt.show()
結果はこちら。
digitsに比べて読みやすい数字画像データが入ってますね。