相変わらずWordCloudの話です。(今回くらいで一旦止めます。)
今回は文字の色を個別に指定します。
前回の記事のコードの抜粋が以下ですが、
colormap 引数で どのような色を使うのかはざっくりと指定できます。(実際の色は単語ごとにランダムに決まる)
これを、「この単語は何色」って具体的に指定しようというのが今回の記事です。
# TF-IDFで Word Cloud作成
wc_1 = WordCloud(
font_path="/Library/Fonts/ipaexg.ttf",
width=600,
height=300,
prefer_horizontal=1,
background_color='white',
include_numbers=True,
colormap='tab20',
).generate_from_frequencies(tfidf_dict)
さて、方法ですが、WordCloudのインスタンスを作る時に、color_func って引数で、色を返す関数を渡すことで実装できます。
ドキュメントの該当ページから引用すると、
次のように word とか font_size とかを受け取る関数を用意しておけばいいようです。
color_funccallable, default=None
Callable with parameters word, font_size, position, orientation, font_path, random_state that returns a PIL color for each word. Overwrites “colormap”.
Using custom colors というページに例もあるので、参考にしながらやってみましょう。
さて、どうやって色をつけるかですが、今回は「品詞」で色を塗り分けることにしてみました。ただ、やってみたら名詞のシェアが高すぎてほぼ全体が同じ色になったので、名詞だけは品詞細分類1までみてわけます。
コードですが、前回の記事で準備したデータを使うので、 形態素分析済みで、TF-IDFも計算できているデータはすでにあるものとします。
まず、単語から品詞を返す関数を作ります。
注: 品詞は本当は文脈にも依存するので、形態素解析したときに取得して保存しておくべきものです。ただ、今回そこは本質でないので、一単語渡したらもう一回MeCabにかけて品詞を返す関数を作りました。
もともと1単語を渡す想定ですが、それがさらに複数の単語にわけられちゃったら1個目の品詞を返します。あまりいい関数ではないですね。
あと、処理の効率化のために関数自体はメモ化しておきます。
from functools import lru_cache
@lru_cache(maxsize=None)
def get_pos(word):
parsed_lines = tagger.parse(word).split("\n")[:-2]
features = [l.split('\t')[1] for l in parsed_lines]
pos = [f.split(',')[0] for f in features]
pos1 = [f.split(',')[1] for f in features]
# 名詞の場合は、 品詞細分類1まで返す
if pos[0] == "名詞":
return f"{pos[0]}-{pos1[0]}"
# 名詞以外の場合は 品詞のみ返す
else:
return pos[0]
(tagger などは前回の記事のコードの中でインスタンス化しているのでこれだけ実行しても動かないので注意してください)
さて、単語を品詞に変換する関数が得られたので、これを使って、単語に対して品詞に応じた色を戻す関数を作ります。
import matplotlib.cm as cm
import matplotlib.colors as mcolors
# 品詞ごとに整数値を返す辞書を作る
pos_color_index_dict = {}
# カラーマップ指定
cmap = cm.get_cmap("tab20")
# これが単語ごとに色を戻す関数
def pos_color_func(word, font_size, position, orientation, random_state=None,
**kwargs):
# 品詞取得
pos = get_pos(word)
# 初登場の品詞の場合は辞書に追加
if pos not in pos_color_index_dict:
pos_color_index_dict[pos] = len(pos_color_index_dict)
color_index = pos_color_index_dict[pos]
# カラーマーップでrgbに変換
rgb = cmap(color_index)
return mcolors.rgb2hex(rgb)
**kwargs が吸収してくれるので、実は font_size とか position とか関数中で使わない変数は引数にも準備しなくていいのですが、
いちおうドキュメントの例を参考に近い形で書いてみました。
これを使って、ワードクラウドを作ります。
# TF-IDFで Word Cloud作成
wc = WordCloud(
font_path="/Library/Fonts/ipaexg.ttf",
width=600,
height=300,
color_func=pos_color_func,
prefer_horizontal=1,
background_color='white',
include_numbers=True,
).generate_from_frequencies(tfidf_dict)
wc.to_image()
変わったのは color_func にさっき作った関数を渡しているのと、 colormap の指定がなくなりました。(指定しても上書きされるので無視されます)
そして出力がこちら。

同じ品詞のものが同色に塗られていますね。
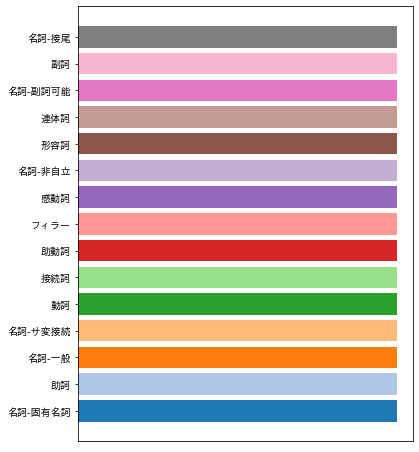
どの品詞が何色なのか、凡例?というか色見本も作ってみました。
たまたま対象のテキストで登場した品詞だけ現れます。
fig = plt.figure(figsize=(6, 8), facecolor="w")
ax = fig.add_subplot(111)
ax.barh(
range(len(pos_color_index_dict)),
[5] * len(pos_color_index_dict),
color=[mcolors.rgb2hex(cmap(i)) for i in range(len(pos_color_index_dict))]
)
ax.set_xticks([])
ax.set_yticks(range(len(pos_color_index_dict)))
ax.set_yticklabels(list(pos_color_index_dict.keys()))
plt.show()