以前の記事で、statsmodelsを使って線形回帰をやったので、今回はポアソン回帰をやってみます。
参考:statsmodelsで重回帰分析
データは久保拓弥先生の、データ解析のための統計モデリング入門 (通称緑本)の第3章から拝借し、
本に載っているのと同じ結果を得ることを目指します。
ちなみに本のコードはRで実装されています。
Rは勉強中なので写経はしましたがそれはそれとして、
今回はいつも使っているpythonのstatsmodelsでやってみます。
データはこちらのサポートページからダウンロードできます。
生態学のデータ解析 – 本/データ解析のための統計モデリング入門
3章の data3a.csv を保存しておきましょう。
このデータは、架空の植物の種子の数に関するもので、
種子の数が$y_i$, 植物のサイズが$x_i$, 施肥処理を行ったかどうかが$f_i$列に格納されています。
そして、種子の個数$y_i$が期待値 $\lambda_i=\exp(\beta_1+\beta_2x_i+\beta_3f)$のポアソン分布に従うと仮定した場合の尤度を最大化するように係数を決定します。
($f$は施肥処理を行ったら1, 行ってない場合は0)
早速やってみましょう。
ドキュメントはこのあたりが参考になります。
statsmodels.genmod.generalized_linear_model.GLM
Model Family に Poisson を指定すると、リンク関数は自動的にlogが選ばれます。
import pandas as pd
import statsmodels.api as sm
# データの読み込み
# ファイルの取得元
# http://hosho.ees.hokudai.ac.jp/~kubo/ce/IwanamiBook.html
df = pd.read_csv("./data3a.csv")
# f 列の値を Tならば 1 , その他(Cのみ)ならば0に符号化
df["fT"] = (df.f == "T").astype(int)
y = df.y
X = df[["x", "fT"]]
# 定数列(1)を作成
X = sm.add_constant(X)
# モデル生成と学習
model = sm.GLM(y, X, family=sm.families.Poisson())
result = model.fit()
# 結果出力
print(result.summary())
# 以下出力結果
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: GLM Df Residuals: 97
Model Family: Poisson Df Model: 2
Link Function: log Scale: 1.0000
Method: IRLS Log-Likelihood: -235.29
Date: Sun, 21 Apr 2019 Deviance: 84.808
Time: 16:36:24 Pearson chi2: 83.8
No. Iterations: 4 Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 1.2631 0.370 3.417 0.001 0.539 1.988
x 0.0801 0.037 2.162 0.031 0.007 0.153
fT -0.0320 0.074 -0.430 0.667 -0.178 0.114
==============================================================================
本のP58に載っているのと全く同じ係数を得ることができました。
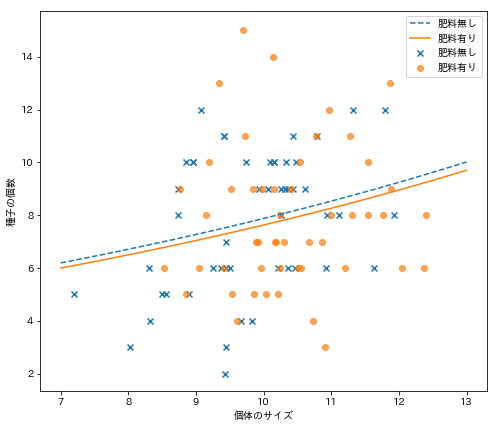
ついでに実際のデータとこのモデルから予測される種子数をプロットして可視化してみます。
import matplotlib.pyplot as plt
import numpy as np
# プロット用のデータ作成
xx = np.linspace(7, 13, 101)
yy0 = np.exp(result.params["const"] + result.params["x"]*xx)
yy1 = np.exp(result.params["const"] + result.params["x"]*xx + result.params["fT"])
# 可視化
fig = plt.figure(figsize=(8, 7))
ax = fig.add_subplot(1, 1, 1)
ax.set_xlabel("個体のサイズ")
ax.set_ylabel("種子の個数")
ax.scatter(X[X.fT == 0]["x"], y[X.fT == 0].values, marker="x", label="肥料無し")
ax.scatter(X[X.fT == 1]["x"], y[X.fT == 1].values, alpha=0.7, label="肥料有り")
ax.plot(xx, yy0, linestyle="--", label="肥料無し")
ax.plot(xx, yy1, label="肥料有り")
plt.legend()
plt.show()
出力結果がこちら。