xkcdってなんだ?って方はこちらをどうぞ。
https://xkcd.com/
wikipedia: xkcd
誰が何の目的で実装されたのか不明ですが、matplotlibにはグラフをxkcdのコミック風に出力する機能があります。
面白いので僕はこういう機能は結構好きです。
ドキュメント: matplotlib.pyplot.xkcd
使い方は簡単で、グラグを書く前、要はplotやbarなどの関数を使う前に、plt.xkcd()を差し込むだけ。
ただ、この手軽さに落とし穴がありました。一回呼び出すと戻せなくなるのです。
(調査にかなり手こずったので、この記事もどちらかというとxkcdの使い方より元への戻し方を伝えたい。)
ドキュメントにも、pcParamsを上書きしてしまうと書いてあります。
Notes
This function works by a number of rcParams, so it will probably override others you have set before.
f you want the effects of this function to be temporary, it can be used as a context manager, for example:
context manager ってのは要は with句の事のようです。(あとでちゃんと調べたい。)
要するに、 with plt.xkcd(): で有効な範囲をあらかじめ絞りましょう
参考に、以下のコードでは二つのグラフをxkcd風に書いた後に、普通のグラフを2つ作成しました。
import matplotlib.pyplot as plt
import numpy as np
data = [5, 4, 3, 2, 1]
label = [f"item {i}" for i in range(5)]
X = np.linspace(0, 2*np.pi, 200)
Y_sin = np.sin(X)
Y_cos = np.cos(X)
fig = plt.figure(figsize=(12, 9), facecolor="w")
# xkcd オプションの影響を局所化するため with で使う。
with plt.xkcd():
ax = fig.add_subplot(2, 2, 1, title="xkcd pie chart")
ax.pie(
data,
labels=label,
autopct='%3.1f%%', # 割合をグラフ中に明記
counterclock=False, # 時計回りに変更
startangle=90, # 開始点の位置を変更
)
ax = fig.add_subplot(2, 2, 2, title="xkcd plot")
ax.plot(X, Y_sin, label="$y=\\sin(x)$")
ax.plot(X, Y_cos, label="$y=\\cos(x)$")
ax.legend()
ax = fig.add_subplot(2, 2, 3, title="normal pie chart")
ax.pie(
data,
labels=label,
autopct='%3.1f%%', # 割合をグラフ中に明記
counterclock=False, # 時計回りに変更
startangle=90, # 開始点の位置を変更
)
ax = fig.add_subplot(2, 2, 4, title="normal plot")
ax.plot(X, Y_sin, label="$y=\\sin(x)$")
ax.plot(X, Y_cos, label="$y=\\cos(x)$")
ax.legend()
plt.show()
出力されたグラフがこちら。
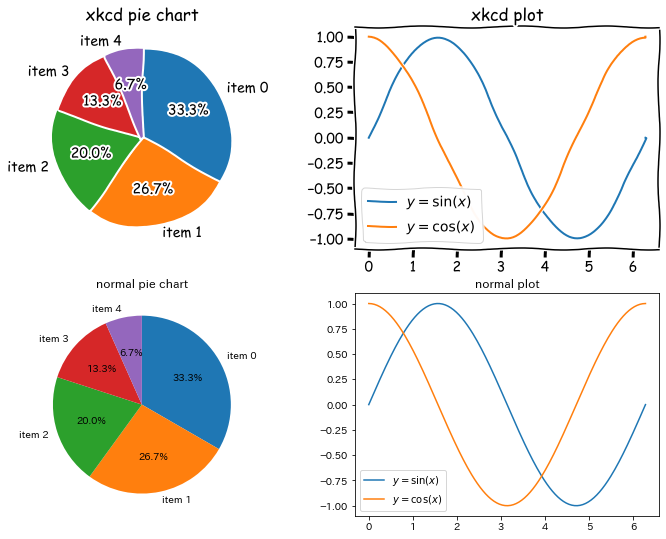
場面を選べば、プレゼンや資料などで使いやすそうなグラフですね。
あと、注意点としては、対応したフォントがないので日本語文字が使えません。
もし、 with を使わずに plt.xkcd() してしまったら、それ以降のグラフは全部、
xkcdモードで出力されてしまいます。
jupyter notebookであれば戻すためにカーネルの再起動が必要になるので気をつけましょう。