Kerasのちょっとした小ネタです。
Kerasで作ったモデルをfitすると、戻り値として損失関数や正解率を格納したHistoryオブジェクトが返されます。
それを使って、学習の進みなどを可視化できます。
例えばこちらの記事を参照: CNNで手書き数字文字の分類
こちらでは可視化だけで10行くらいのコードになっています。
で、改めてHistoryの中身をみてみると、DataFrameに変換できる形式であることに気づきました。
長いので、実データは {数値のリスト} に置換しましたが、次のようなイメージです。
print(history.history)
'''
{'val_loss': {数値のリスト},
'val_acc': {数値のリスト},
'loss': {数値のリスト},
'acc': {数値のリスト}
'''
これは容易にDataFrameに変換できます。
print(pd.DataFrame(history.history))
'''
val_loss val_acc loss acc
0 0.106729 0.9677 0.590888 0.811850
1 0.072338 0.9764 0.227665 0.931233
2 0.059273 0.9800 0.174741 0.948033
3 0.047335 0.9837 0.149136 0.955500
4 0.042737 0.9859 0.132351 0.960167
5 0.039058 0.9868 0.121810 0.964600
6 0.034511 0.9881 0.110556 0.967050
7 0.032818 0.9882 0.105487 0.967867
8 0.032139 0.9893 0.100333 0.970167
9 0.030482 0.9898 0.095932 0.971383
10 0.027904 0.9900 0.089120 0.973267
11 0.028368 0.9898 0.086760 0.973683
'''
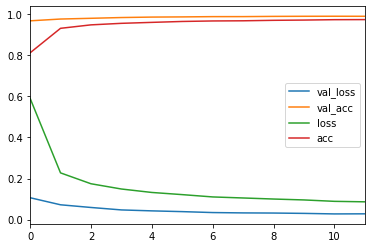
DataFrameになると、これ自体を分析しやすいですし、さらに非常に容易に可視化できます。
history_df = pd.DataFrame(history.history)
history_df.plot()
plt.show()
たったこれだけです。以前の記事の可視化に比べると非常に楽ですね。
出力はこのようになります。