Scipyが使える今となっては使う機会はほぼありませんが、
一様分布から正規分布に従う乱数を作成できる方法である、ボックス=ミュラー法(Box–Muller’s method)を紹介します。
正規分布は累積分布関数やその逆関数が初等関数では表現できず、
最近紹介した逆関数法で乱数を生成するのは少々困難です。
そこでこのボックス=ミュラー法が使われます。
参考:自然科学の統計学(東京大学出版会)の 11.3 正規乱数の発生法
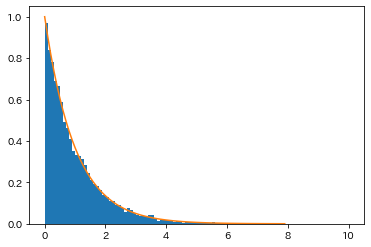
まず、確率変数$X$,$Y$が互いに独立で、共に$(0,1)$上の一様分布に従うとします。
この時、
$$
\begin{align}
Z_1 & = \sqrt{-2\log{X}}\cos{2\pi Y},\\
Z_2 & = \sqrt{-2\log{X}}\sin{2\pi Y}
\end{align}
$$
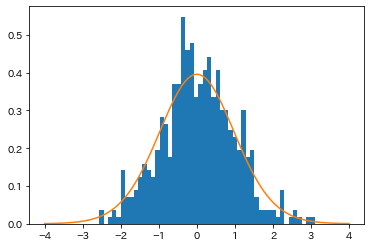
とすると、$Z_1$と$Z_2$は標準正規分布$N(0,1)$に従う互いに独立な確率変数になります。
厳密な証明は今回は省略します。
ただ、数式をみれば、正規分布の確率密度関数が指数関数の形をしているので$\log$が出てくるのも、
円周率も出てくるなど円に関係しそうな気配があるので三角関数が出てくるのもなんとなく納得性があります。
ただ、「互いに独立な」ってのは正直驚きます。
$Z_1^2+Z_2^2=-2\log{X}$って関係式が成り立つのに独立ってことはないんじゃないかと思えますね。
(この$X$が定数ではないのがキモで、$0<X<1$から、$-2\log{X}$が
非常に大きな値も含めて実に自由に動くので独立性が生まれるようです。)
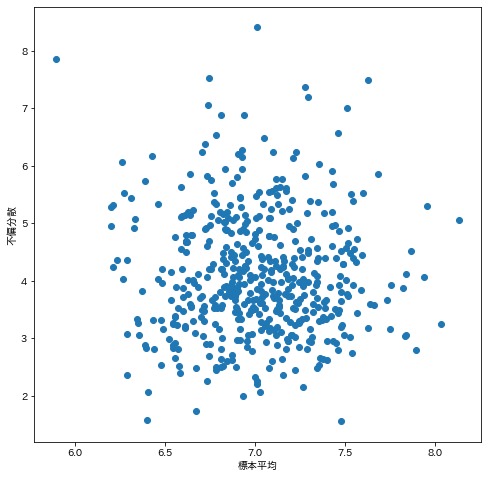
ここだけ実験して相関係数が0に近いことを確認しておきましょう。
import numpy as np
# 一様分布に従うX, Yをそれぞれ10000個生成
X = np.random.rand(10000)
Y = np.random.rand(10000)
# Z_1, Z_2 を計算
Z_1 = np.sqrt(-2*np.log(X))*np.cos(2*np.pi*Y)
Z_2 = np.sqrt(-2*np.log(X))*np.sin(2*np.pi*Y)
# 相関係数を算出
print(np.corrcoef(Z_1, Z_2)[0, 1])
# -0.0043281961119066865
確かに独立っぽいですね。
散布図等も出してみましたが何か特別な関係性は見当たらないようです。