ここまでの数回の記事でいろいろな方法で特定の確率分布に従う乱数を得る方法を紹介してきましたが、
SciPyで生成する方法についてきちんと紹介してないことに気づいたので書いておきます。
numpyについてはこちらで書いてます。
といってもこれまでの実験中で使っている通り、SciPyのstatsモジュールに定義されている各確率分布ごとに、
rvsという関数があるのでそれを使うだけです。
確率分布が連続であっても、離散であっても同じ名前です。
ドキュメント:
(連続の例)正規分布の場合 scipy.stats.norm
(離散の例)二項分布の場合 scipy.stats.binom
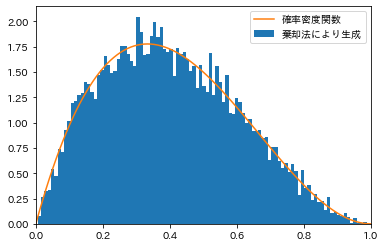
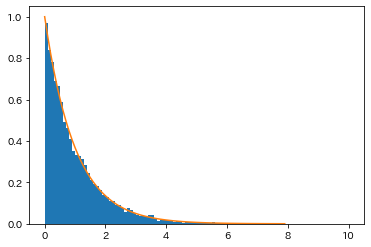
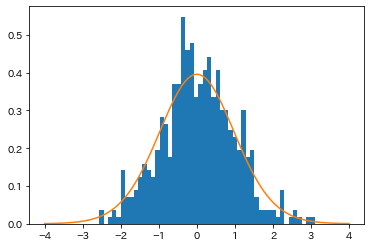
最近の記事でも一様分布からのサンプリングで使いまくってるでほぼ説明不要なのですが、
以下の例のように各確率分布に従う乱数を得ることができます。
from scipy.stats import norm
from scipy.stats import binom
print(norm.rvs(loc=2, scale=5, size=5))
# [-1.46417053 -2.76659505 0.80006028 4.83473226 4.05597588]
print(binom.rvs(n=20, p=0.3, size=10))
# [9 7 7 5 9 5 8 4 9 8]
rvs ってなんの略だろう? 特にsは何かということが気になって調べていたのですが、
今の所、明確な答えは見つけられていません。(なんの略語かわからないと覚えにくい。)
sampling かな? と思っていたこともあるのですが、GitHubでソースを見ると _rvs_sampling ってのも登場するので違いそう。
チュートリアルの中に、
random variables (RVs)
という記載があるので、random variablesの略である可能性が一番高いかなと思います。